Multi-threading is an extensive and complex subject, and many good reference texts on the subject exist. The C++ multi-threading is built upon the facilities offered by the pthreads library (cf. Nichols, B, et al.'s Pthreads Programming, O'Reilly ). However, in line with C++'s current-day philosophy the multi-threading implementation offered by the language offers a high level interface to multi-threading, and using the raw pthread building blocks is hardly ever necessary (cf. Williams, A. (2019): C++ Concurrency in action).
This chapter covers the facilities for multi-threading as supported by C++. Although the coverage aims at providing the tools and examples allowing you to create your own multi-threaded programs, coverage necessarily is far from complete. The topic of multi threading is too extensive for that. The mentioned reference texts provide a good starting point for any further study of multi threading.
A thread of execution (commonly abbreviated to a thread) is a single flow of control within a program. It differs from a separately executed program, as created by the fork(1) system call in the sense that threads all run inside one program, while fork(1) creates independent copies of a running program. Multi-threading means that multiple tasks are being executed in parallel inside one program, and no assumptions can be made as to which thread is running first or last, or at what moment in time. Especially when the number of threads does not exceed the number of cores, each thread may be active at the same time. If the number of threads exceed the number of cores, the operating system will resort to task switching, offering each thread time slices in which it can perform its tasks. Task switching takes time, and the law of diminishing returns applies here as well: if the number of threads greatly exceeds the number of available cores (also called overpopulation), then the overhead incurred may exceed the benefit of being able to run multiple tasks in parallel.
Since all threads are running inside one single program, all threads share the program's data and code. When the same data are accessed by multiple threads, and at least one of the threads is modifying these data, access must be synchronized to avoid that threads read data while these data are being modified by other threads, and to avoid that multiple threads modify the same data at the same time.
So how do we run a multi-threaded program in C++? Let's look at hello world, the multi-threaded way:
1: #include <iostream>
2: #include <thread>
3:
4: void hello()
5: {
6: std::cout << "hello world!\n";
7: }
8:
9: int main()
10: {
11: std::thread hi(hello);
12: hi.join();
13: }
thread is included, informing the compiler
about the existence of the class std::thread (cf. section 20.1.2);
std::thread hi object is created. It is provided
with the name of a function (hello) which will be called in a separate
thread. Actually, the second thread, running hello, is immediately started
when a std::thread is defined this way;
main function itself also represents a thread: the program's
first thread. It should wait until the second thread has finished. This
is realized in line 12, where hi.join() waits until the thread hi
has finished its job. Since there are no further statements in main, the
program itself ends immediately thereafter.
hello itself, defined in lines 4 through 7, is
trivial: it simply inserts the text `hello world' into cout, and
terminates, thus ending the second thread.
C++'s main tool for creating multi-threaded programs is the class
std::thread, and some examples of its use have already been shown at the
beginning of this chapter.
Characteristics of individual threads can be queried from the
std::this_thread namespace. Also, std::this_thread offers some control
over the behavior of an individual thread.
To synchronize access to shared data C++ offers mutexes (implemented
by the class std::mutex) and condition variables (implemented by the
class std::condition_variable).
Members of these classes may throw system_error objects (cf. section
10.9) when encountering a low-level error condition.
namespace std::this_thread
contains functions that are uniquely associated with the currently running
thread.
Before using the namespace this_thread the <thread> header file must
be included.
Inside the std::this_thread namespace several free functions are defined,
providing information about the current thread or that can be used to control
its behavior:
thread::id this_thread::get_id() noexcept:thread::id that identifies the currently
active thread of execution. For an active thread the returned id is unique
in the sense that it maps 1:1 to the currently active thread, and is not
returned by any other thread. If the thread is currently not running then the
default thread::id object is returned by the std::thread
object's get_id member.
void yield() noexcept:this_thread::yield() the current thread is
briefly suspended, allowing other (waiting) threads to start.
void sleep_for(chrono::duration<Rep, Period> const &relTime)
noexcept:this_thread::sleep_for(...) it is suspended
for the amount of time that's specified in its argument. E.g.,
std::this_thread::sleep_for(std::chrono::seconds(5));
void sleep_until(chrono::time_point<Clock, Duration> const &absTime)
noexcept:absTime is in the past. The next example has the same effect as the
previous example:
// assume using namespace std this_thread::sleep_until(chrono::system_clock().now() + chrono::seconds(5));
Conversely, the sleep_until call in the next example immediately
returns:
this_thread::sleep_until(chrono::system_clock().now() - chrono::seconds(5));
std::thread. Each object of this class handles a separate
thread.
Before using Thread objects the <thread> header file must be included.
Thread objects can be constructed in various ways:
thread() noexcept:thread object. As it receives no
function to execute, it does not start a separate thread of execution. It is
used, e.g., as a data member of a class, allowing class objects to start a
separate thread at some later point in time;
thread(thread &&tmp) noexcept:tmp, while tmp, if it runs a thread, loses control over its
thread. Following this, tmp is in its default state, and the newly created
thread is responsible for calling, e.g., join.
explicit thread(Fun &&fun, Args &&...args):thread's constructor immediately following
its first (function) argument. Additional arguments are passed with their
proper types and values to fun. Following the thread object's
construction, a separately running thread of execution is started.
The notation Arg &&...args indicates that any additional arguments are
passed as is to the function. The types of the arguments that are passed to
the thread constructor and that are expected by the called function must
match: values must be values, references must be reference, r-value references
must be r-value references (or move construction must be supported). The
following example illustrates this requirement:
1: #include <iostream>
2: #include <thread>
3:
4: using namespace std;
5:
6: struct NoMove
7: {
8: NoMove() = default;
9: NoMove(NoMove &&tmp) = delete;
10: };
11:
12: struct MoveOK
13: {
14: int d_value = 10;
15:
16: MoveOK() = default;
17: MoveOK(MoveOK const &) = default;
18:
19: MoveOK(MoveOK &&tmp)
20: {
21: d_value = 0;
22: cout << "MoveOK move cons.\n";
23: }
24: };
25:
26: void valueArg(int value)
27: {}
28: void refArg(int &ref)
29: {}
30: void r_refArg(int &&tmp)
31: {
32: tmp = 100;
33: }
34: void r_refNoMove(NoMove &&tmp)
35: {}
36: void r_refMoveOK(MoveOK &&tmp)
37: {}
38:
39: int main()
40: {
41: int value = 0;
42:
43: std::thread(valueArg, value).join();
44: std::thread(refArg, ref(value)).join();
45: std::thread(r_refArg, move(value)).join();
46:
47: // std::thread(refArg, value);
48:
49: std::thread(r_refArg, value).join();
50: cout << "value after r_refArg: " << value << '\n';
51:
52: // std::thread(r_refNoMove, NoMove());
53:
54: NoMove noMove;
55: // std::thread(r_refNoMove, noMove).join();
56:
57: MoveOK moveOK;
58: std::thread(r_refMoveOK, moveOK).join();
59: cout << moveOK.d_value << '\n';
60: }
std::thread: with
the functions running the threads expecting matching argument types.
refArg. Note that this problem was solved in line 43
by using the std::ref function.
int values and
class-types supporting move operations can be passed as values to functions
expecting r-value references. In this case notice that the functions expecting
the r-value references do not access the provided arguments (except for the
actions performed by their move constructors), but use move construction to
create temporary values or objects on which the functions operate.
NoMove struct doesn't offer
a move constructor.
struct Demo
{
int d_value = 0;
void fun(int value)
{
d_value = value;
cout << "fun sets value to " << value << "\n";
}
};
int main()
{
Demo demo;
thread thr{&Demo::fun, ref(demo), 12 };
thr.join();
cout << "demo's value: " << demo.d_value << '\n'; // 12
thr = thread{&Demo::fun, &demo, 42 };
thr.join();
cout << "demo's value: " << demo.d_value << '\n'; // 42
thr = thread{&Demo::fun, demo, 77 };
thr.join();
cout << "demo's value: " << demo.d_value << '\n'; // 42: the thread
// copied demo
}
Be careful when passing local variables as arguments to thread objects: if the thread continues to run when the function whose local variables are used terminates, then the thread suddenly uses wild pointers or wild references, as the local variables no longer exist. To prevent this from happening (illustrated by the next example) do as follows:
thread constructor, or
join on the thread object to ensure that the thread has
finished within the local variable's lifetime.
1: #include <iostream>
2: #include <thread>
3: #include <string>
4: #include <chrono>
5:
6: void threadFun(std::string const &text)
7: {
8: for (size_t iter = 1; iter != 6; ++iter)
9: {
10: std::cout << text << '\n';
11: std::this_thread::sleep_for(std::chrono::seconds(1));
12: }
13: }
14:
15: std::thread safeLocal()
16: {
17: std::string text = "hello world";
18: return std::thread(threadFun, std::string{ text });
19: }
20:
21: int main()
22: {
23: std::thread local(safeLocal());
24: local.join();
25: std::cout << "safeLocal has ended\n";
26: }
In line 18 be sure not to call std::ref(text) instead of
std::string{ text }.
If the thread cannot be created a std::system_error exception is
thrown.
Since this constructor not only accepts functions but also function objects as its first argument, a local context may be passed to the function object's constructor. Here is an example of a thread receiving a function object using a local context:
#include <iostream>
#include <thread>
#include <array>
using namespace std;
class Functor
{
array<int, 30> &d_data;
int d_value;
public:
Functor(array<int, 30> &data, int value)
:
d_data(data),
d_value(value)
{}
void operator()(ostream &out)
{
for (auto &value: d_data)
{
value = d_value++;
out << value << ' ';
}
out << '\n';
}
};
int main()
{
array<int, 30> data;
Functor functor{ data, 5 };
thread funThread{ functor, ref(cout) };
funThread.join();
};
std::thread does not provide a copy constructor.
The following members are available:
thread &operator=(thread &&tmp) noexcept:
If the operator's left-hand side operand (lhs) is a joinable thread, thenterminateis called. Otherwise,tmpis assigned to the operator's lhs andtmp'sstate is changed to the thread's default state (i.e.,thread()).
void detach():joinable (see below) to return true. The thread for
which detach is called continues to run. The (e.g., parent) thread calling
detach continues immediately beyond the detach-call. After calling
object.detach(), `object' no longer represents the (possibly still
continuing but now detached) thread of execution. It is the detached thread's
implementation's responsibility to release its resources when its execution
ends.
Since detach disconnects a thread from the running program, e.g.,
main no longer can wait for the thread's completion. As a program
ends when main ends, its still running detached threads also stop, and
a program may not properly finish all its threads, as demonstrated by
the following example:
#include <thread>
#include <iostream>
#include <chrono>
void fun(size_t count, char const *txt)
{
for (; count--; )
{
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::cout << count << ": " << txt << std::endl;
}
}
int main()
{
std::thread first(fun, 5, "hello world");
first.detach();
std::thread second(fun, 5, "a second thread");
second.detach();
std::this_thread::sleep_for(std::chrono::milliseconds(400));
std::cout << "leaving" << std::endl;
}
A detached thread may very well continue to run after the function that launched it has finished. Here, too, you should be very careful not to pass local variables to the detached thread, as their references or pointers will be undefined once the function defining the local variables terminates:
#include <iostream>
#include <thread>
#include <chrono>
using namespace std;
using namespace chrono;
void add(int const &p1, int const &p2)
{
this_thread::sleep_for(milliseconds(200));
cerr << p1 << " + " << p2 << " = " << (p1 + p2) << '\n';
}
void run()
{
int v1 = 10;
int v2 = 20;
// thread(add, ref(v1), ref(v2)).detach(); // DON'T DO THIS
thread(add, int(v1), int(v2)).detach(); // this is OK: own copies
}
int main()
{
run();
this_thread::sleep_for(seconds(1));
}
id get_id() const noexcept:thread::id() is returned. Otherwise, the thread's unique ID
(also obtainable from within the thread via this_thread::get_id()) is
returned.
unsigned thread::hardware_concurrency() noexecpt:
void join():joinable to return true. If the thread for which
join is called hasn't finished yet then the thread calling join will
be suspended (also called blocked) until the thread for which join is
called has completed. Following its completion the object whose join
member was called no longer represents a running thread, and its get_id
member will return std::thread::id().
This member was used in several examples shown so far. As noted: when
main ends while a joinable thread is still running, terminate is
called, aborting the program.
bool joinable() const noexcept:object.get_id() != id(), where object is the
thread object for which joinable was called.
native_handle_type native_handle():pthread_getschedparam and
pthread_setschedparam to get/set the thread's scheduling policy and
parameters.
void swap(thread &other) noexcept:thread object for which swap was called and
other are swapped. Note that threads may always be swapped, even when
their thread functions are currently being executed.
Things to note:
join. E.g.,
void doSomething();
int main()
{
thread(doSomething); // nothing happens??
thread(doSomething).join(); // doSomething is executed??
}
This similar to the situation we encountered in section 7.5:
the first statement doesn't define an anonymous thread object at all. It
simply defines the thread object doSomething. Consequently,
compilation of the second statement fails, as there is no thread(thread &)
constructor. When the first statement is omitted, the doSomething function
is executed by the second statement. If the second statement is omitted, a
default constructed thread object by the name of doSomething is
defined.
thread object(thread(doSomething));
the move constructor is used to transfer control from an anonymous thread
executing doSomething to the thread object. Only after object's
construction has completed doSomething is started in the separate thread.
packaged_task and a
future (cf., respectively, sections 20.11 and 20.8).
A thread ends when the function executing a thread finishes. When a
thread object is destroyed while its thread function is still running,
terminate is called, aborting the program's end. Bad news: the destructors
of existing objects aren't called and exceptions that are thrown are left
uncaught. This happens in the following program as the thread is still active
when main ends:
#include <iostream>
#include <thread>
void hello()
{
while (true)
std::cout << "hello world!\n";
}
int main()
{
std::thread hi(hello);
}
There are several ways to solve this problem. One of them is discussed in
the next section.
The thread_local keyword provides this intermediate data level. Global
variables declared as thread_local are global within each individual
thread. Each thread owns a copy of the thread_local variables, and may
modify them at will. A thread_local variable in one thread is completely
separated from that variable in another thread. Here is an example:
1: #include <iostream>
2: #include <thread>
3:
4: using namespace std;
5:
6: thread_local int t_value = 100;
7:
8: void modify(char const *label, int newValue)
9: {
10: cout << label << " before: " << t_value << ". Address: " <<
11: &t_value << '\n';
12: t_value = newValue;
13: cout << label << " after: " << t_value << '\n';
14: }
15:
16: int main()
17: {
18: thread(modify, "first", 50).join();
19: thread(modify, "second", 20).join();
20: modify("main", 0);
21: }
thread_local variable t_value is defined. It is
initialized to 100, and that becomes the initial value for each separately
running thread;
modify is defined. It assigns
a new value to t_value;
modify.
t_value being 100, and then modifies it without affecting the values of
t_value used by other threads.
Note that, although the t_value variables are unique to each thread,
identical addresses may be shown for them. Since each thread uses its own
stack, these variables may occupy the same relative locations within their
respective stacks, giving the illusion that their physical addresses are
identical.
void childActions();
void doSomeWork();
void parent()
{
thread child(childActions);
doSomeWork();
child.join();
}
However, maybe doSomeWork can't complete its work, and throws an
exception, to be caught outside of parent. This, unfortunately, ends
parent, and child.join() is missed. Consequently, the program aborts
because of a thread that hasn't been joined.
Clearly, all exceptions must be caught, join must be called, and the
exception must be rethrown. But parent cannot use a function try-block, as
the thread object is already out of scope once execution reaches the matching
catch-clause. So we get:
void childActions();
void doSomeWork();
void parent()
{
thread child(childActions);
try
{
doSomeWork();
child.join();
}
catch (...)
{
child.join();
throw;
}
}
This is ugly: suddenly the function's code is clobbered with a
try-catch clause, as well as some unwelcome code-duplication.
This situation can be avoided using object based programming. Like, e.g., unique pointers, which use their destructors to encapsulate the destruction of dynamically allocated memory, we can use a comparable technique to encapsulate thread joining in an object's destructor.
By defining the thread object inside a class we're sure that by the time
the our object goes out of scope, even if the childActions function
throws an exception, the thread's join member is called. Here are the bare
essentials of our JoinGuard class, providing the join-guarantee (using
in-line member implementations for brevity):
1: #include <thread>
2:
3: class JoinGuard
4: {
5: std::thread d_thread;
6:
7: public:
8: JoinGuard(std::thread &&threadObj)
9: :
10: d_thread(std::move(threadObj))
11: {}
12: ~JoinGuard()
13: {
14: if (d_thread.joinable())
15: d_thread.join();
16: }
17: };
thread object, which is moved, in line 10, to JoinGuard's d_thread
data member.
JoinGuard object ceases to exist, its destructor (line
12) makes sure the thread is joined if it's still joinable (lines 14 and 15).
JoinGuard could be used:
1: #include <iostream>
2: #include "joinguard.h"
3:
4: void childActions();
5:
6: void doSomeWork()
7: {
8: throw std::runtime_error("doSomeWork throws");
9: }
10:
11: void parent()
12: {
13: JoinGuard{std::thread{childActions}};
14: doSomeWork();
15: }
16:
17: int main()
18: try
19: {
20: parent();
21: }
22: catch (std::exception const &exc)
23: {
24: std::cout << exc.what() << '\n';
25: }
childActions is declared. Its implementation (not
provided here) defines the child thread's actions.
main function (lines 17 through 25) provides the function
try-block to catch the exception thrown by parent;
parent function defines (line 13) an anonymous JoinGuard,
receiving an anonymous thread object. Anonymous objects are used, as the
parent function doesn't need to access them anymore.
doSomeWork is called, which throws an exception. This
ends parent, but just before that JoinGuard's destructor makes sure
that the child-thread has been joined.
std::thread the class std::jthread can be
used.
Before using jthread objects the <thread> header file must be
included.
Objects of the class jthread act like thread objects, but a
jthread thread automatically joins the thread that activated
jthread. Moreover, in some situations jthread threads can directly
be ended.
Once a jthread object receiving a function defining the thread's actions
has been constructed that function immediately starts as a separate thread.
If that function ends by returning a value then that value is ignored. If the
function throws an exception the program ends by calling
std::terminate. Alternatively, if the function should communicate a return
value or an exception to, e.g., the function starting the jthread a
std::promise (cf. section (20.12)) can be used or it can modify
variables which are shared with other threads (see also sections 20.2
and 20.5).
The class jthread offers these constructors:
jthread() noexcept:jthread object that doesn't
start a thread. It could be used as a data member of a class, allowing class
objects to start the jthread at some later point in time;
explicit jthread(Function &&function, Args &&...args):function. The function receives as its first
argument the return value of jthread's member get_stop_token (see
below), followed by the args parameters (if present). If function's
first argument is not a std::stop_token then function, merely
receiving the args parameter values as its arguments. Arguments are passed
to function with their proper types and values (see the example shown
below at the description of the jthread member request_stop;)
jthread supports move construction and move assignment,
but does not offer copy construction and copy assignment.
The following members are available and operate like the identically named
std::thread members. Refer to section 20.1.2 for their descriptions:
void detach();
id get_id() const noexcept;
unsigned thread::hardware_concurrency() noexecpt
void join();
bool joinable() const noexcept;
native_handle_type native_handle();
void swap(thread &other) noexcept.
The following members are specific to jthread, allowing other threads to
end the thread started by jthread:
std::stop_source get_stop_source() noexcept:jthread's std::stop_source.
std::get_stop_token get_stop_token() const noexcept:jthread's std::stop_token.
bool request_stop() noexcept:jthread object. The
function operates atomically: it can be called from multiple threads
without causing race conditions. It returns true if the stop
request was successfully issued. It returns false if a stop
request has already been issued, which may also happen if
request_stop was issued by different threads, and another thread
is still in the process of ending jthread's thread.request_stop then std::stop_callback functions (see
the next section) that were registered for the thread's stop state are
synchroneously called. If those callback functions throw exceptions
then std::terminate is called. Also, any waiting condition
variables that are associated with the jthread's stop state end
their waiting states.
Here is a short program illustrating request_stop:
1: #include <iostream>
2: #include <thread>
3: #include <chrono>
4: using namespace std;
5:
6: void fun(std::stop_token stop)
7: {
8: while (not stop.stop_requested())
9: {
10: cout << "next\n";
11: this_thread::sleep_for(1s);
12: }
13: }
14:
15: int main()
16: {
17: jthread thr(fun);
18:
19: this_thread::sleep_for(3s);
20:
21: thr.request_stop();
22:
23: // thr.join() not required.
24: }
jthread thread starts, receiving function fun
as its argument;
fun defines a std::stop_token parameter, jthread will
start that function. It performs (line 8) a while loop that
continues until stop's stop_requested returns true. The loop
itself shows a brief output line (line 10) followed by a one-second
sleep (line 11);
main function, having started the thread, sleeps for three
seconds (line 19), and then (line 21) issues a stop-request,
ending the thread.
When running the program three lines containing next are displayed.
std::stop_callback objects the
<stop_token> header file must be included.
In addition to merely ending thread functions via jthread's request_stop
member function it's also possible to associate callback
functions with request_stop, which are executed when request_stop is
called. In situations where callback functions are registered when the
thread function has already been stopped the callback functions are
immediately called when they are being registered (registering callback
functions is covered below).
Note that multiple callback functions can be registered. However, the order in
which these callback functions are run once the thread is stopped is not
defined. Moreover, exceptions may not leave callback functions or the program
ends by calling std::terminate.
Callback functions are registered by objects of the class
std::stop_callback. The class stop_callback offers the following
constructors:
explicit stop_callback(std::stop_token const &st,
Function &&cb) noexcept;
explicit stop_callback(std::stop_token &&st, Function &&cb) noexcept;
Notes:
Function can be the name of a (void) function without parameters or
it can be an (anonymous or existing) object offering a parameter-less
(void) function call operator. The functions do not necessarily have
to be void functions, but their return values are ignored;
noexcept is only used if Function is also declared as
noexcept (if Function is the name of a functor-class then
noexcept is used if its constructor is declared with
noexcept);
stop_callback does not offer copy/move construction and
assignment.
Here is the example used in the previous section, this time defining a callback function. When running this program its output is
next
next
next
stopFun called via stop_callback
1: void fun(std::stop_token stop)
2: {
3: while (not stop.stop_requested())
4: {
5: cout << "next\n";
6: this_thread::sleep_for(1s);
7: }
8: }
9:
10: void stopFun()
11: {
12: cout << "stopFun called via stop_callback\n";
13: }
14:
15: int main()
16: {
17: jthread thr(fun);
18:
19: stop_callback sc{ thr.get_stop_token(), stopFun };
20:
21: this_thread::sleep_for(3s);
22:
23: thr.request_stop();
24: thr.join();
25: }
The function fun is identical to the one shown in the previous
section, but main defines (line 19) the stop_callback object sc,
passing it thr's get_stop_token's return value and the address of the
function stopFun, defined in lines 10 thru 13. In this case once
request_stop is called (line 23) the callback function stopFun is
called as well.
Before using mutexes the <mutex> header file must be included.
One of the key characteristics of multi-threaded programs is that threads may share data. Functions running as separate threads have access to all global data, and may also share the local data of their parent threads. However, unless proper measures are taken, this may easily result in data corruption, as illustrated by the following simulation of some steps that could be encountered in a multi-threaded program:
---------------------------------------------------------------------------
Time step: Thread 1: var Thread 2: description
---------------------------------------------------------------------------
0 5
1 starts T1 active
2 writes var T1 commences writing
3 stopped Context switch
4 starts T2 active
5 writes var T2 commences writing
6 10 assigns 10 T2 writes 10
7 stopped Context switch
8 assigns 12 T1 writes 12
9 12
----------------------------------------------------------------------------
In this example, threads 1 and 2 share variable var, initially having
the value 5. At step 1 thread 1 starts, and starts to write a value into
var. However, it is interrupted by a context switch, and thread 2 is
started (step 4). Thread 2 also wants to write a value into var, and
succeeds until time step 7, when another context switch takes place. By now
var is 10. However, thread 1 was also in the process of writing a value
into var, and it is given a chance to complete its work: it assigns 12
to var in time step 8. Once time step 9 is reached, thread 2 proceeds on
the (erroneous) assumption that var must be equal to 10. Clearly, from the
point of view of thread 2 its data have been corrupted.
In this case data corruption was caused by multiple threads accessing the same data in an uncontrolled way. To prevent this from happening, access to shared data should be protected in such a way that only one thread at a time may access the shared data.
Mutexes are used to prevent the abovementioned kinds of problems by offering a guarantee that data are only accessed by the thread that could lock the mutex that is used to synchronize access to those data.
Exclusive data access completely depends on cooperation between the threads. If thread 1 uses mutexes, but thread 2 doesn't, then thread 2 may freely access the common data. Of course that's bad practice, which should be avoided.
It is stressed that although using mutexes is the programmer's responsibility, their implementation isn't: mutexes offer the necessary atomic calls. When requesting a mutex-lock the thread is blocked (i.e., the mutex statement does not return) until the lock has been obtained by the requesting thread.
Apart from the class std::mutex the class
std::recursive_mutex is available. When a recursive_mutex is called
multiple times by the same thread it increases its lock-count. Before other
threads may access the protected data the recursive mutex must be unlocked
again that number of times. Moreover, the classes
std::timed_mutex
and
std::recursive_timed_mutex
are available. Their locks expire when released, but also after a certain
amount of time.
The members of the mutex classes perform atomic actions: no context
switch occurs while they are active. So when two threads are trying to
lock a mutex only one can succeed. In the above example: if both threads
would use a mutex to control access to var thread 2 would not have been
able to assign 12 to var, with thread 1 assuming that its value was 10. We
could even have two threads running purely parallel (e.g., on two separate
cores). E.g.:
-------------------------------------------------------------------------
Time step: Thread 1: Thread 2: description
-------------------------------------------------------------------------
1 starts starts T1 and T2 active
2 locks locks Both threads try to
lock the mutex
3 blocks... obtains lock T2 obtains the lock,
and T1 must wait
4 (blocked) processes var T2 processes var,
T1 still blocked
5 obtains lock releases lock T2 releases the lock,
and T1 immediately
obtains the lock
6 processes var now T1 processes var
7 releases lock T1 also releases the lock
-------------------------------------------------------------------------
Although mutexes can directly be used in programs, this rarely happens. It is more common to embed mutex handling in locking classes that make sure that the mutex is automatically unlocked again when the mutex lock is no longer needed. Therefore, this section merely offers an overview of the interfaces of the mutex classes. Examples of their use will be given in the upcoming sections (e.g., section 20.3).
All mutex classes offer the following constructors and members:
mutex() constexpr:constexpr constructor is the only available
constructor;
~mutex():unlock member;
void lock():lock is
called for a recursive mutex a system_error is thrown if the thread
already owns the lock. Recursive mutexes increment their internal
lock count;
bool try_lock() noexcept:true is returned, otherwise false. If the
calling thread already owns the lock true is also returned, and in this
case a recursive mutex also increments its internal lock count;
void unlock() noexcept:system_error is thrown if the thread does not own the
lock. A recursive mutex decrements its interal lock count, releasing
ownership of the mutex once the lock count has decayed to zero;
The timed-mutex classes (timed_mutex, recursive_timed_mutex) also offer
these members:
bool try_lock_for(chrono::duration<Rep, Period> const
&relTime) noexcept:true is returned,
otherwise false. If the calling thread already owns the lock true is
also returned, and in this case a recursive timed mutex also increments its
internal lock count. The Rep and Duration types are inferred from
the actual relTime argument. E.g.,
std::timed_mutex timedMutex; timedMutex.try_lock_for(chrono::seconds(5));
bool try_lock_until(chrono::time_point<Clock,
Duration> const &absTime) noexcept:absTime has passed. If ownership is obtained, true is returned,
otherwise false. If the calling thread already owns the lock true is
also returned, and in this case a recursive timed mutex also increments its
internal lock count. The Clock and Duration types are inferred
from the actual absTime argument. E.g.,
std::timed_mutex timedMutex; timedMutex.try_lock_until(chrono::system_clock::now() + chrono::seconds(5));
std::once_flag and the
std::call_once function, introduced in this section, the
<mutex> header file must be included.
In single threaded programs the initialization of global data does not
necessarily occur at one point in code. An example is the initialization of
the object of a singleton class (cf. Gamma et al. (1995), Design Patterns,
Addison-Wesley). Singleton classes may define a single static pointer data
member Singleton *s_object, pointing to the singleton's object, and may
offer a static member instance, implemented something like this:
Singleton &Singleton::instance()
{
return s_object ?
s_object
:
(s_object = new Singleton);
}
With multi-threaded programs this approach immediately gets complex. For
example, if two threads call instance at the same time, while s_object
still equals 0, then both may call new Singleton, resulting in one
dynamically allocated Singleton object becoming unreachable. Other
threads, called after s_object was initialized for the first time, may
either return a reference to that object, or may return a reference to the
object initialized by the second thread. Not exactly the expected behavior of
a singleton.
Mutexes (cf. section 20.2) can be used to solve these kinds of problems,
but they result in some overhead and inefficiency, as the mutex must be
inspected at each call of Singleton::instance.
When variables must dynamically be initialized, and the initialization should
take place only once the std::once_flag type and the std::call_once
function should be used.
The call_once function expects two or three arguments:
once_flag variable, keeping track of the
actual initialization status. The call_once function simply returns if
the once_flag indicates that initialization already took place;
call_once's third argument.
instance function can
now easily be designed (using in-class implementations for brevity):
class Singleton
{
static std::once_flag s_once;
static Singleton *s_singleton;
...
public:
static Singleton *instance()
{
std::call_once(s_once, []{s_singleton = new Singleton;} );
return s_singleton;
}
...
};
However, there are additional ways to initialize data, even for multi-threaded programs:
constexpr
keyword (cf. section 8.1.4.1), satisfying the requirements for constant
initialization. In this case, a static object, initialized using that
constructor, is guaranteed to be initialized before any code is run as part of
the static initialization phase. This is used by std::mutex, as it
eliminates the possibility of race conditions when global mutexes are
initialized.
#include <iostream>
struct Cons
{
Cons()
{
std::cout << "Cons called\n";
}
};
void called(char const *time)
{
std::cout << time << "time called() activated\n";
static Cons cons;
}
int main()
{
std::cout << "Pre-1\n";
called("first");
called("second");
std::cout << "Pre-2\n";
Cons cons;
}
/*
Displays:
Pre-1
firsttime called() activated
Cons called
secondtime called() activated
Pre-2
Cons called
*/
This feature causes a thread to wait automatically if another thread is
still initializing the static data (note that non-static data never cause
problems, as non-static local variables only exist within their own thread of
execution).
std::shared_mutex) are available after
including the <shared_mutex> header file. Shared mutex types behave like
timed_mutex types and optionally have the characteristics described below.
The class shared_mutex provides a non-recursive mutex with shared
ownership semantics, comparable to, e.g., the shared_ptr type.
A program using shared_mutexes is undefined if:
shared_mutex;
shared_mutex.
Shared mutex types provide a shared lock ownership mode. Multiple threads can
simultaneously hold a shared lock ownership of a shared_mutex type of
object. But no thread can hold a shared lock while another thread holds an
exclusive lock on the same shared_mutex object, and vice-versa.
Shared mutexes are useful in situations where multiple threads (consumers) want to access information for reading: the consumers don't want to change the data, but merely want to retrieve them. At some point another thread (the producer) wants to modify the data. At that point the producer requests exclusive access to the data, and is forced to wait until all consumers have released their locks. While the producer waits for the exclusive lock, new consumers' requests for shared locks remain pending until the producer has released the exclusive lock. Thus, reading is possible for many threads, but for writing the exclusive lock guarantees that no other threads can access the data.
The type shared_mutex offers the following members providing shared lock
ownership. To obtain exclusive ownership omit the _shared from the
following member functions:
void lock_shared():
void unlock_shared():
bool try_lock_shared():try_lock_shared immediately returns. Returns true if the shared
ownership lock was acquired, false otherwise. An implementation may fail
to obtain the lock even if it is not held by any other thread. Initially the
calling thread may not yet own the mutex;
bool try_lock_shared_for(rel_time):rel_time. If the time specified by
rel_time is less than or equal to rel_time.zero(), the member attempts
to obtain ownership without blocking (as if by calling
try_lock_shared()). The member shall return within the time interval
specified by rel_time only if it has obtained shared ownership of the mutex
object. Returns true if the shared ownership lock was acquired, false
otherwise. Initially the calling thread may not yet own the mutex;
bool try_lock_shared_until(abs_time):abs_time has passed. If the time specified by
abs_time has already passed then the member attempts to obtain ownership
without blocking (as if by calling try_lock_shared()). Returns true
if the shared ownership lock was acquired, false otherwise. Initially the
calling thread may not yet own the mutex;
<mutex> header file must be included.
Whenever threads share data, and at least one of the threads may change common data, mutexes should be used to prevent threads from using the same data synchronously.
Usually locks are released at the end of action blocks. This requires explicit
calls to the mutexes' unlock function, which introduces comparable
problems as we've seen with the thread's join member.
To simplify locking and unlocking two mutex wrapper classes are available:
std::lock_guard:unlock of the mutexes they control;
std::unique_lock:lock_guard;
The class lock_guard offers a limited, but useful interface:
lock_guard<Mutex>(Mutex &mutex):lock_guard object the mutex type (e.g.,
std::mutex, std::timed_mutex, std::shared_mutex) is specified, and a mutex
of the indicated type is provided as its argument. The construction blocks
until the lock_guard object owns the lock. The lock_guard's destructor
automatically releases the mutex lock.
lock_guard<Mutex>(Mutex &mutex, std::adopt_lock_t):lock_guard. The mutex lock is released again by the
lock_guard's destructor. At construction time the mutex must already be
owned by the calling thread. Here is an illustration of how it can be used:
1: void threadAction(std::mutex &mut, int &sharedInt)
2: {
3: std::lock_guard<std::mutex> lg{mut, std::adopt_lock_t()};
4: // do something with sharedInt
5: }
threadAction receives a reference to a
mutex. Assume the mutex owns the lock;
lock_guard. Even
though we don't explicitly use the lock_guard object, an object should be
defined to prevent the compiler from destroying an anonymous object before the
function ends;
lock_guard's destructor.
mutex_type:lock_guard<Mutex> types also define the type mutex_type: it is a
synonym of the Mutex type that is passed to the lock_guard's
constructor.
Here is a simple example of a multi-threaded program using lock_guards
to prevent information inserted into cout from getting mixed.
bool oneLine(istream &in, mutex &mut, int nr)
{
lock_guard<mutex> lg(mut);
string line;
if (not getline(in, line))
return false;
cout << nr << ": " << line << endl;
return true;
}
void io(istream &in, mutex &mut, int nr)
{
while (oneLine(in, mut, nr))
this_thread::yield();
}
int main(int argc, char **argv)
{
ifstream in(argv[1]);
mutex ioMutex;
thread t1(io, ref(in), ref(ioMutex), 1);
thread t2(io, ref(in), ref(ioMutex), 2);
thread t3(io, ref(in), ref(ioMutex), 3);
t1.join();
t2.join();
t3.join();
}
As with lock_guard, a mutex-type must be specified when defining
objects of the class std::unique_lock. The class
unique_lock is much more elaborate than the basic lock_guard class
template. Its interface does not define a copy constructor or overloaded
assignment operator, but it does define a move constructor and a move
assignment operator. In the following overview of unique_lock's interface
Mutex refers to the mutex-type that is specified when defining a
unique_lock:
unique_lock() noexcept:mutex
object. It must be assigned a mutex (e.g., using move-assignment) before
it can do anything useful;
explicit unique_lock(Mutex &mutex):unique_lock with an existing Mutex object, and
calls mutex.lock();
unique_lock(Mutex &mutex, defer_lock_t) noexcept:unique_lock with an existing Mutex object, but
does not call mutex.lock(). Call it by passing a defer_lock_t object
as the constructor's second argument, e.g.,
unique_lock<mutex> ul(mutexObj, defer_lock_t())
unique_lock(Mutex &mutex, try_to_lock_t) noexcept:unique_lock with an existing Mutex object, and
calls mutex.try_lock(): the constructor won't block if the mutex cannot be
locked;
unique_lock(Mutex &mutex, adopt_lock_t) noexcept:unique_lock with an existing Mutex object,
and assumes that the current thread has already locked the mutex;
unique_lock(Mutex &mutex, chrono::duration<Rep, Period> const
&relTime) noexcept:Mutex object by
calling mutex.try_lock_for(relTime). The specified mutex type must
therefore support this member (e.g., it is a std::timed_mutex). It could
be called like this:
std::unique_lock<std::timed_mutex> ulock(timedMutex,
std::chrono::seconds(5));
unique_lock(Mutex &mutex, chrono::time_point<Clock, Duration> const
&absTime) noexcept:Mutex object by
calling mutex.try_lock_until(absTime). The specified mutex type must
therefore support this member (e.g., it is a std::timed_mutex).
This constructor could be called like this:
std::unique_lock<std::timed_mutex> ulock(
timedMutex,
std::chrono::system_clock::now() + std::chrono::seconds(5)
);
void lock():unique_lock is obtained. If no mutex is currently managed, then a
system_error exception is thrown.
Mutex *mutex() const noexcept:unique_lock (a nullptr is returned if no mutex object is currently
associated with the unique_lock object.)
explicit operator bool() const noexcept:true if the unique_lock owns a locked mutex, otherwise
false is returned;
unique_lock& operator=(unique_lock &&tmp) noexcept:unlock member, whereafter tmp's state is transferred to the left-hand
operand;
bool owns_lock() const noexcept:true if the unique_lock owns the mutex, otherwise
false is returned;
Mutex *release() noexcept:unique_lock object, discarding that association;
void swap(unique_lock& other) noexcept:unique_lock and other;
bool try_lock():unique_lock, returning true if this succeeds, and false
otherwise. If no mutex is currently associated with the unique_lock
object, then a system_error exception is thrown;
bool try_lock_for(chrono::duration<Rep, Period> const
&relTime):Mutex object
managed by the unique_lock object by calling the mutex's
try_lock_for(relTime) member. The specified mutex type must therefore
support this member (e.g., it is a std::timed_mutex);
bool try_lock_until(chrono::time_point<Clock,
Duration> const &absTime):Mutex object
managed by the unique_lock object by calling the mutex's
mutex.try_lock_until(absTime) member. The specified mutex type must
therefore support this member (e.g., it is a std::timed_mutex);
void unlock():system_error exception is thrown if the unique_lock object does not
own the mutex.
In addition to the members of the classes std::lock_guard and
std::unique_lock the functions std::lock and
std::try_lock are available. These functions can be
used to prevent deadlocks, the topic of the next section.
lock_guards is defining it as an anonymous
object:
void Class::notLocked()
{
lock_guard<mutex>{d_mutex};
// using data available to multiple threads
}
In cases like these, since the lock_guard is defined as an anonymous
object, it's immediately destroyed after its construction offering no guard
against multiple threads using the shared data.
Traditionally this situation is solved by explicitly defining an object. The object's name is irrelevant, because it's used nowhere else, resulting in constructions like
void Class::lockedOK()
{
lock_guard<mutex> guard{d_mutex};
// using data available to multiple threads
}
But in this context the name's irrelevant and not used nowhere elsew in
the function.
Since the C++26 standard, however, a generalized alternative approach
is available. It's called
name-independent declaration
Very simple (and broadly applicable), requiring --std=c++26 or
beyond, which is supported since g++-14.
The 'name' _ (a single underscore) results in a name-independent
declaration. It's definitely not a name we would use for 'common'
variables, but starting with the C++26 standard a variable named `_' implies a
name-independent declaration. So in 'lockedOK' we can now do:
void Class::lockedOK()
{
lock_guard<mutex> _{d_mutex};
// using data available to multiple threads
}
and we never have to think again about how to name a required (but not
used by us) variable or object. As long as there's no ambiguity it's even
possible to define multiple `_' variables or objects. As long as they're not
being used by name it's possible to define, e.g.,
void neverUsed()
{
int _{12};
int _{43}; // a different int because of the initialization
auto _ = 42; // 'auto' also works fine
auto _("hello world"); // a string...
}
But in practice, use name independent declarations as illustrated in the
above lockedOK function.
std::lock and std::try_lock functions that can
be used to help preventing such situations.
Before these functions can be used the <mutex> header file must be
included
In the following overview L1 &l1, ... represents one or more
references to objects of lockable types:
void std::lock(L1 &l1, ...):li
objects. If a lock could not be obtained for at least one of the
objects, then all locks obtained so far are relased, even if the
object for which no lock could be obtained threw an exception;
int std::try_lock(L1 &l1, ...):try_lock members. If all
locks could be obtained, then -1 is returned. Otherwise the (0-based)
index of the first argument which could not be locked is returned,
releasing all previously obtained locks.
As an example consider the following little multi-threaded program: The
threads use mutexes to obtain unique access to cout and to an int
value. However, fun1 first locks cout (line 7), and then value
(line 10); fun2 first locks value (line 16) and then cout (line
19). Clearly, if fun1 has locked cout fun2 can't obtain the lock
until fun1 has released it. Unfortunately, fun2 has locked value,
and the functions only release their locks when returning. But in order to
access the information in value fun1 it must have obtained a lock on
value, which it can't, as fun2 has already locked value: the
threads are waiting for each other, and neither thread gives in.
1:
2: int value;
3: mutex valueMutex;
4: mutex coutMutex;
5:
6: void fun1()
7: {
8: lock_guard<mutex> lg1(coutMutex);
9: cout << "fun 1 locks cout\n";
10:
11: lock_guard<mutex> lg2(valueMutex);
12: cout << "fun 1 locks value\n";
13: }
14:
15: void fun2()
16: {
17: lock_guard<mutex> lg1(valueMutex);
18: cerr << "fun 2 locks value\n";
19:
20: lock_guard<mutex> lg2(coutMutex);
21: cout << "fun 2 locks cout\n";
22: }
23:
24: int main()
25: {
26: thread t1(fun1);
27: fun2();
28: t1.join();
29: }
30:
A good recipe for avoiding deadlocks is to prevent nested (or multiple) mutex
lock calls. But if multiple mutexes must be used, always obtain the locks in
the same order. Rather than doing this yourself, std::lock and
std::try_lock should be used whenever possible to obtain multiple mutex
locks. These functions accept multiple arguments, which must be lockable types
like lock_guard, unique_lock, or even a plain mutex. The previous
deadlocking program, can be modified to call std::lock to lock both
mutexes. In this example using one single mutex would also work, but the
modified program now looks as similar as possible to the previous
program. Note how in lines 10 and 21 a different
ordering of the unique_locks arguments was used: it is not necessary to
use an identical argument order when calling std::lock or
std::try_lock.
1: int value;
2: mutex valueMutex;
3: mutex coutMutex;
4:
5: void fun1()
6: {
7: scoped_lock sl{ coutMutex, valueMutex };
8: cout << "fun 1 locks cout\n";
9: sleep(1);
10: cout << "fun 1 locks value\n";
11: }
12:
13: void fun2()
14: {
15: scoped_lock sl{ valueMutex, coutMutex };
16: cout << "fun 2 locks value\n";
17: sleep(1);
18: cout << "fun 2 locks cout\n";
19: }
20:
21: int main()
22: {
23: thread t1(fun1);
24: fun2();
25: t1.join();
26: }
27: // Displays:
28: // fun 2 locks value
29: // fun 2 locks cout
30: // fun 1 locks cout
31: // fun 1 locks value
std::shared_lock, after including the
<shared_mutex> header file.
An object of the type std::shared_lock controls the shared ownership of a
lockable object within a scope. Shared ownership of the lockable object may be
acquired at construction time or thereafter, and once acquired, it may be
transferred to another shared_lock object. Objects of type shared_lock
cannot be copied, but move construction and assignment is supported.
The behavior of a program is undefined if the contained pointer to a mutex
(pm) has a non-zero value and the lockable object pointed to by pm does
not exist for the entire remaining lifetime of the shared_lock
object. The supplied mutex type must be a shared_mutex or a type having
the same characteristics.
The type shared_lock offers the following constructors, destructor and
operators:
shared_lock() noexcept:shared_lock which is not owned
by a thread and for which pm == 0;
explicit shared_lock(mutex_type &mut):mut.lock_shared(). The
calling thread may not already own the lock. Following the construction pm
== &mut, and the lock is owned by the current thread;
shared_lock(mutex_type &mut, defer_lock_t) noexcept:pm to &mut, but the calling thread
does not own the lock;
shared_lock(mutex_type &mut, try_to_lock_t):mut.try_lock_shared(). The calling thread may not already own the
lock. Following the construction pm == &mut, and the lock may or may not
be owned by current thread, depending on the return value of
try_lock_shared;
shared_lock(mutex_type &mut, adopt_lock_t):pm == &mut, and the
lock is owned by the current thread;
shared_lock(mutex_type &mut,
chrono::time_point<Clock, Duration> const &abs_time):Clock and
Duration are types specifying a clock and absolute time (cf. section
4.2). It can be called if the calling thread does not already own
the mutex. It calls mut.try_lock_shared_until(abs_time). Following the
construction pm == &mut, and the lock may or may not be owned by current
thread, depending on the return value of try_lock_shared_until;
shared_lock(mutex_type &mut,
chrono::duration<Rep, Period> const &rel_time):Clock and
Period are types specifying a clock and relative time (cf. section
4.2). It can be called if the calling thread does not already own
the mutex. It calls mut.try_lock_shared_for(abs_time). Following the
construction pm == &mut, and the lock may or may not be owned by current
thread, depending on the return value of try_lock_shared_for;
shared_lock(shared_lock &&tmp) noexcept:tmp to the
newly constructed shared_lock. Following the construction tmp.pm == 0
and tmp no longer owns the lock;
~shared_lock():pm->unlock_shared() is called;
shared_lock &operator=(shared_lock &&tmp) noexcept
(The move assignment operator calls pm->unlock_shared and then
transfers the information in tmp to the
current shared_lock object. Following this tmp.pm == 0
and tmp no longer owns the lock;)
explicit operator bool () const noexcept:shared_lock object owns the lock.
The following members are provided:
void lock():pm->lock_shared(), after which the current tread owns the
shared lock. Exceptions may be thrown from lock_shared, and otherwise if
pm == 0 or if the current thread already owns the lock;
mutex_type *mutex() const noexcept:pm;
mutex_type *release() noexcept:pm, which is equal to zero after
calling this member. Also, the current object no longer owns the lock;
void swap(shared_lock &other) noexcept:other shared_lock
objects. There is also a free member swap, a function template, swapping
two shared_lock<Mutex> objects, where Mutex represents the mutex type
for which the shared lock objects were instantiated: void
swap(shared_lock<Mutex> &one, shared_lock<Mutex> &two) noexcept;
bool try_lock():pm->try_lock_shared(), returning this call's return value.
Exceptions may be thrown from try_lock_shared, and
otherwise if pm == 0 or if the current thread already owns the lock;
bool try_lock_for(const chrono::duration<Rep, Period>&
rel_time):Clock and Period are types specifying a
clock and relative time (cf. section 4.2). It calls
mut.try_lock_shared_for(abs_time). Following the call the lock may or may
not be owned by current thread, depending on the return value of
try_lock_shared_until. Exceptions may be thrown from
try_lock_shared_for, and otherwise if pm == 0 or if the current thread
already owns the lock;
bool try_lock_until(const chrono::time_point<Clock,
Duration>& abs_time):Clock and Duration are types specifying
a clock and absolute time (cf. section 4.2). It calls
mut.try_lock_shared_until(abs_time), returning its return value. Following
the call the lock may or may not be owned by current thread, depending on the
return value of try_lock_shared_until. Exceptions may be thrown from
try_lock_shared_until, and otherwise if pm == 0 or if the current
thread already owns the lock;
void unlock():scoped_lock can be used to lock multiple semaphores at once,
where the scoped_lock ensures that deadlocks are avoided.
The scoped_lock also has a default constructor, performing no actions, so
it's up to the software engineer to define scoped_lock objects with at
least one mutex. Before using scoped_lock objects the <mutex>
header file must be included. Adapting the example from section
20.3.2: both functions define a scoped_lock (note that the order
in which the mutexes are specified isn't relevant), and deadlocks are do not
occur:
1:
2: int value;
3: mutex valueMutex;
4: mutex coutMutex;
5:
6: void fun1()
7: {
8: unique_lock<mutex> lg1(coutMutex, defer_lock);
9: unique_lock<mutex> lg2(valueMutex, defer_lock);
10:
11: lock(lg1, lg2);
12:
13: cout << "fun 1 locks cout\n";
14: cout << "fun 1 locks value\n";
15: }
16:
17: void fun2()
18: {
19: unique_lock<mutex> lg1(coutMutex, defer_lock);
20: unique_lock<mutex> lg2(valueMutex, defer_lock);
21:
22: lock(lg2, lg1);
23:
24: cout << "fun 2 locks cout\n";
25: cout << "fun 2 locks value\n";
26: }
27:
28: int main()
29: {
30: thread t1(fun1);
31: thread t2(fun2);
32: t1.join();
33: t2.join();
34: }
35:
Thus, instead of using lock_guard objects, scoped_lock objects can be
used. It's a matter of taste whether lock_guards or scoped_locks
should be preferred when only one mutex is used. Maybe scoped_lock should
be preferred, since it always works....
Before condition variables can be used the <condition_variable> header
file must be included.
To start our discussion, consider a classic producer-consumer scenario: the producer generates items which are consumed by a consumer. The producer can only produce a certain number of items before its storage capacity has filled up and the client cannot consume more items than the producer has produced.
At some point the producer's storage capacity has filled to the brim, and the producer has to wait until the client has at least consumed some items, thereby creating space in the producer's storage. Similarly, the consumer cannot start consuming until the producer has at least produced some items.
Implementing this scenario only using mutexes (data locking) is not an attractive option, as merely using mutexes forces a program to implement the scenario using polling: processes must continuously (re)acquire the mutex's lock, determine whether they can perform some action, followed by the release of the lock. Often there's no action to perform, and the process is busy acquiring and releasing the mutex's lock. Polling forces threads to wait until they can lock the mutex, even though continuation might already be possible. The polling interval could be reduced, but that too isn't an attractive option, as that increases the overhead associated with handling the mutexes (also called `busy waiting').
Condition variables can be used to prevent polling. Threads can use condition variables to notify waiting threads that there is something for them to do. This way threads can synchronize on data values (states).
As data values may be modified by multiple threads, threads still need to use mutexes, but only for controlling access to the data. In addition, condition variables allow threads to release ownership of mutexes until a certain value has been obtained, until a preset amount of time has been passed, or until a preset point in time has been reached.
The prototypical setup of threads using condition variables looks like this:
lock the mutex
while the required condition has not yet been attained (i.e., is false):
wait until being notified
(this automatically releasing the mutex's lock).
once the mutex's lock has been reacquired, and the required condition
has been attained:
process the data
release the mutex's lock.
lock the mutex
while the required condition has not yet been attained:
do something to attain the required condition
notify waiting threads (that the required condition has been attained)
release the mutex's lock.
This protocol hides a subtle initial synchronization requirement. The consumer
will miss the producer's notification if it (i.e., the consumer) hasn't yet
entered its waiting state. So waiting (consumer) threads should start
before notifying (producer) threads. Once threads have started, no
assumptions can be made anymore about the order in which any of the condition
variable's members (notify_one, notify_all, wait, wait_for, and
wait_until) are called.
Condition variables come in two flavors: objects of the class
std::condition_variable are used in combination
with objects of type unique_lock<mutex>. Because of
optimizations which are available for this specific combination using
condition_variables is somewhat more efficient than using the more
generally applicable class
std::condition_variable_any, which may be
used with any (e.g., user supplied) lock type.
Condition variable classes (covered in detail in the next two sections) offer
members like wait, wait_for, wait_until, notify_one and notify_all
that may concurrently be called. The notifying members are always atomically
executed. Execution of the wait members consists of three atomic parts:
wait
call).
wait-members the previously waiting thread
has reacquired the mutex's lock.
In addition to the condition variable classes the following free function and
enum type is provided:
void
std::notify_all_at_thread_exit(condition_variable &cond,
unique_lock<mutex> lockObject):cond are notified. It is good practice to exit the thread as
soon as possible after calling notify_all_at_thread_exit.
Waiting threads must verify that the thread they were waiting for has
indeed ended. This is usually realized by first obtaining the lock on
lockObject, followed by verifying that the condition
they were waiting for is true and that the lock was not
reacquired before notify_all_at_thread_exit was called.
std::cv_status:cv_status enum is used by several member functions of the
condition variable classes (cf. sections 20.4.1 and
20.4.2):
namespace std
{
enum class cv_status
{
no_timeout,
timeout
};
}
std::condition_variable merely offers a
default constructor. No copy constructor or overloaded assignment operator is
provided.
Before using the class condition_variable the <condition_variable>
header file must be included.
The class's destructor requires that no thread is blocked by the thread
destroying the condition_variable. So all threads waiting on a
condition_variable must be notified before a condition_variable
object's lifetime ends. Calling notify_all (see below) before a
condition_variable's lifetime ends takes care of that, as the
condition_variable's thread releases its lock of the mutex variable,
allowing one of the notified threads to lock the mutex.
In the following member-descriptions a type Predicate indicates that a
provided Predicate argument can be called as a function without arguments,
returning a bool. Also, other member functions are frequently referred
to. It is tacitly assumed that all member referred to below were called using
the same condition variable object.
The class condition_variable supports several wait members, which
block the thread until notified by another thread (or after a configurable
waiting time). However, wait members may also spuriously unblock, without
having reacquired the lock. Therefore, returning from wait members threads
should verify that the required condition is actually true. If not,
again calling wait may be appropriate. The next piece of pseudo code
illustrates this scheme:
while (conditionNotTrue())
condVariable.wait(&uniqueLock);
The class condition_variable's members are:
void notify_one() noexcept:wait member called by other threads returns. Which one
actually returns cannot be predicted.
void notify_all() noexcept:wait members called by other threads unblock their wait
states. Of course, only one of them will subsequently succeed in
reacquiring the condition variable's lock object.
void wait(unique_lock<mutex>& uniqueLock):wait the current thread must have acquired the lock
of uniqueLock. Calling wait releases the lock, and the current
thread is blocked until it has received a notification from another
thread, and has reacquired the lock.
void wait(unique_lock<mutex>& uniqueLock, Predicate pred):template
<typename Predicate>.
The template's type is automatically derived from the function's
argument type and does not have to be specified explicitly.
Before calling wait the current thread must have acquired the lock
of uniqueLock. As long as `pred' returns false
wait(lock) is called.
cv_status wait_for(unique_lock<mutex> &uniqueLock,
std::chrono::duration<Rep, Period> const &relTime):template <typename Rep, typename Period>.
The template's types are automatically derived from the types of the
function's arguments and do not have to be specified explicitly.
E.g., to wait for at most 5 seconds wait_for can be called like
this:
cond.wait_for(&unique_lock, std::chrono::seconds(5));
This member returns when being notified or when the time interval
specified by relTime has passed.
When returning due to a timeout, std::cv_status::timeout is
returned, otherwise std::cv_status::no_timeout is
returned.
Threads should verify that the required data condition has been met
after wait_for has returned.
bool wait_for(unique_lock<mutex> &uniqueLock,
chrono::duration<Rep, Period> const &relTime, Predicate
pred):template <typename Rep, typename Period, typename
Predicate>.
The template's types are automatically derived from the types of the
function's arguments and do not have to be specified explicitly.
As long as pred returns false, the previous wait_for member is
called. If the previous member returns cv_status::timeout, then
pred is returned, otherwise true.
cv_status wait_until(unique_lock<mutex>& uniqueLock,
chrono::time_point<Clock, Duration> const &absTime):template <typename Clock, typename Duration>.
The template's types are automatically derived from the types of the
function's arguments and do not have to be specified explicitly.
E.g., to wait until 5 minutes after the current time wait_until can
be called like this:
cond.wait_until(&unique_lock, chrono::system_clock::now() +
std::chrono::minutes(5));
This function acts identically to the wait_for(unique_lock<mutex>
&uniqueLock, chrono::duration<Rep, Period> const &relTime) member
described earlier, but uses an absolute point in time, rather than a
relative time specification.
This member returns when being notified or when the time interval
specified by relTime has passed.
When returning due to a timeout, std::cv_status::timeout is
returned, otherwise std::cv_status::no_timeout is
returned.
bool wait_until(unique_lock<mutex> &lock,
chrono::time_point<Clock, Duration> const &absTime,
Predicate pred):template <typename Clock, typename Duration, typename Predicate>.
The template's types are automatically derived from the types of the
function's arguments and do not have to be specified explicitly.
As long as pred returns false, the previous wait_until member
is called. If the previous member returns cv_status::timeout, then
pred is returned, otherwise true.
true when
wait-members of condition variables return.
condition_variable the class
std::condition_variable_any can be used with
any (e.g., user supplied) lock type, and not just with the stl-provided
unique_lock<mutex>.
Before using the class condition_variable_any the <condition_variable>
header file must be included.
The functionality that is offered by condition_variable_any is identical
to the functionality offered by the class condition_variable, albeit that
the lock-type that is used by condition_variable_any is not
predefined. The class condition_variable_any therefore requires the
specification of the lock-type that must be used by its objects.
In the interface shown below this lock-type is referred to as
Lock. Most of condition_variable_any's members are defined as
member templates, defining a Lock type as one of its parameters. The
requirements of these lock-types are identical to those of the stl-provided
unique_lock, and user-defined lock-type implementations should provide at
least the interface and semantics that is also provided by unique_lock.
This section merely presents the interface of the class
condition_variable_any. As its interface offers the same members as
condition_variable (allowing, where applicable, passing any lock-type
instead of just unique_lock to corresponding members), the reader is
referred to the previous section for a description of the semantics of the
class members.
Like condition_variable, the class condition_variable_any only
offers a default constructor. No copy constructor or overloaded assignment
operator is provided.
Also, like condition_variable, the class's destructor requires that no
thread is blocked by the current thread. This implies that all other (waiting)
threads must have been notified; those threads may, however, subsequently
block on the lock specified in their wait calls.
Note that, in addition to Lock, the types Clock, Duration, Period,
Predicate, and Rep are template types, defined just like the identically
named types mentioned in the previous section.
Assuming that MyMutex is a user defined mutex type, and that MyLock is
a user defined lock-type (cf. section 20.3 for details about
lock-types), then a condition_variable_any object can be defined and used
like this:
MyMutex mut;
MyLock<MyMutex> ul(mut);
condition_variable_any cva;
cva.wait(ul);
These are the class condition_variable_any's members:
void notify_one() noexcept;
void notify_all() noexcept;
void wait(Lock& lock);
void wait(Lock& lock, Predicate pred);
cv_status wait_until(Lock& lock, const
chrono::time_point<Clock, Duration>& absTime);
bool wait_until(Lock& lock, const chrono::time_point<Clock, Duration>&
absTime, Predicate pred);
cv_status wait_for(Lock& lock, const chrono::duration<Rep,
Period>& relTime);
bool wait_for(Lock& lock, const chrono::duration<Rep, Period>&
relTime,) Predicate pred;
consumer loop:
- wait until there's an item in store,
then reduce the number of stored items
- remove the item from the store
- increment the number of available storage locations
- do something with the retrieved item
producer loop:
- produce the next item
- wait until there's room to store the item,
then reduce the number of available storage locations
- store the item
- increment the number of stored items
It is important that the two storage administrative tasks (registering the number of available items and available storage locations) are either performed by the client or by the producer. For the consumer `waiting' means:
Semaphore, offering members
wait and notify_all. For a more extensive discussion of semaphores see
Tanenbaum, A.S. (2016)
Structured Computer Organization, Pearson Prentice-Hall.
As a brief summary: semaphores restrict the number of threads that can access a resource of limited size. It ensures that the number of threads that add items to the resource (the producers) can never exceed the resource's maximum size, or it ensures that the number of threads that retrieve items from the resource (the consumers) can never exceed the resource's current size. Thus, in a producer/consumer design two semaphores are used: one to control access to the resource by the producers, and one to control access to the resource by the consumers.
For example, say we have ten producing threads, as well as ten consumers, and a lockable queue that must not grow bigger than 1000 items. Producers try to push one item at a time; consumers try to pop one.
The data member containing the actual count is called d_available. It is
protected by mutex d_mutex. In addition a condition_variable
d_condition is defined:
mutable std::mutex d_mutex; // mutable because of its use in
// 'size_t size() const'
std::condition_variable d_condition;
size_t d_available;
The waiting process is implemented through its member function wait:
1: void Semaphore::wait()
2: {
3: std::unique_lock<std::mutex> lk(d_mutex); // get the lock
4: while (d_available == 0)
5: d_condition.wait(lk); // internally releases the lock
6: // and waits, on exit
7: // acquires the lock again
8: --d_available; // dec. available
9: } // the lock is released
In line 5 d_condition.wait releases the lock. It waits until receiving
a notification, and re-acquires the lock just before returning. Consequently,
wait's code always has complete and unique control over d_available.
What about notifying a waiting thread? This is handled in lines 4 and
5 of the member function notify_all:
1: void Semaphore::notify_all()
2: {
3: std::lock_guard<std::mutex> lk(d_mutex); // get the lock
4: if (d_available++ == 0)
5: d_condition.notify_all(); // use notify_one to notify one other
6: // thread
7: } // the lock is released
At line 4 d_available is always incremented; by using a postfix
increment it can simultaneously be tested for being zero. If it was initially
zero then d_available is now one. A thread waiting until d_available
exceeds zero may now continue. A waiting thread is notified by calling
d_condition.notify_one. In situations where multiple threads are waiting
`notify_all' can also be used.
Using the facilities of the class Semaphore whose constructor expects
an initial value of its d_available data member, the classic
consumer-producer paradigm can now be implemented using
multi-threading (A more elaborate example of the producer-consumer
program is found in the yo/threading/examples/events.cc file in the
C++ Annotations's source archive):
Semaphore available(10);
Semaphore filled(0);
std::queue<size_t> itemQueue;
std::mutex qMutex;
void consumer()
{
while (true)
{
filled.wait();
// mutex lock the queue:
{
std::lock_guard lg(qMutex);
size_t item = itemQueue.front();
itemQueue.pop();
}
available.notify_all();
process(item); // not implemented here
}
}
void producer()
{
size_t item = 0;
while (true)
{
++item;
available.wait();
// mutex lock the queue with multiple consumers
{
std::lock_guard lg(qMutex);
itemQueue.push(item);
}
filled.notify_all();
}
}
int main()
{
thread consume(consumer);
thread produce(producer);
consume.join();
produce.join();
}
Note that a mutex is used to avoid simultaneous access to the queue by
multiple threads. Consider the situation where the queue contains 5 items: in
that situation the semaphores allow the consumer and the producer to access
the queue, but to avoid currupting the queue only one of them may modify the
queue at a time. This is realized by both threads obtaining the std::mutex
qMutex lock before modifying the queue.
<atomic> header
file must be included.
When data are shared among multiple threads, data corruption is usually
prevented using mutexes. To increment a simple int using this strategy
code as shown below is commonly used:
{
lock_guard<mutex> lk{ intVarMutex };
++intVar;
}
The compound statement is used to limit the lock_guard's lifetime, so
that intVar is only locked for a short little while.
This scheme is not complex, but at the end of the day having to define a
lock_guard for every single use of a simple variable, and having to define
a matching mutex for each simple variable is a bit annoying and cumbersome.
C++ offers a way out through the use of atomic data types. Atomic data types are available for all basic types, and also for (trivial) user defined types. Trivial types are (see also section 23.6.2) all scalar types, arrays of elements of a trivial type, and classes whose constructors, copy constructors, and destructors all have default implementations, and their non-static data members are themselves of trivial types.
The class template std::atomic<Type> is available for all
built-in types, including pointer types. E.g., std::atomic<bool> defines
an atomic bool type. For many types alternative somewhat shorter
type names are available. E.g, instead of std::atomic<unsigned short> the
type std::atomic_ushort can be used. Refer to the atomic header file
for a complete list of alternate names.
If Trivial is a user-defined trivial type then
std::atomic<Trivial>
defines an atomic variant of Trivial: such a type does not require
a separate mutex to synchronize access by multiple threads.
Objects of the class template std::atomic<Type> cannot directly be copied
or assigned to each other. However, they can be initialized by values of type
Type, and values of type Type can also directly be assigned to
std::atomic<Type> objects. Moreover, since atomic<Type> types offer
conversion operators returning their Type values, an atomic<Type>
objects can also be assigned to or initialized by another atomic<Type>
object using a static_cast:
atomic<int> a1 = 5;
atomic<int> a2{ static_cast<int>(a1) };
The class std::atomic<Type> provides several public members, shown
below. Non-member (free) functions operating on atomic<Type> objects are
also available.
The std::memory_order enumeration defines the following symbolic
constants, which are used to specify ordering constraints of atomic operations:
memory_order_acq_rel: the operation must be a read-modify-write
operation, combining memory_order_acquire and
memory_order_release;
memory_order_acquire: the operation is an acquire operation. It
synchronizes with a release operation that wrote the same memory
location;
memory_order_consume: the operation is a consume operation on the
involved memory location;
memory_order_relaxed: no ordering constraints are provided by the
operation;
memory_order_release: the operation is a release operation. It
synchronizes with acquire operations on the same location;
memory_order_sec_cst: the default memory order specification for all
operations. Memory storing operations use memory_order_release,
memory load operations use memory_order_acquire, and
read-modify-write operations use memory_order_acq_rel.
The memory order cannot be specified for the overloaded operators provided by
atomic<Type>. Otherwise, most atomic member functions may also be
given a final memory_order argument. Where this is not available it is
explictly mentioned at the function's description.
Here are the standard available std::atomic<Type> member functions:
bool compare_exchange_strong(Type
¤tValue, Type newValue) noexcept:newValue using
byte-wise comparisons. If equal (and true is returned) then
newValue is stored in the atomic object; if unequal (and false
is returned) the object's current value is stored in
currentValue;
bool compare_exchange_weak(Type &oldValue,
Type newValue) noexcept:newValue using
byte-wise comparisons. If equal (and true is returned),
then newValue is stored in the atomic object; if unequal, or
newValue cannot be atomically assigned to the current object
false is returned and the object's current value is stored in
currentValue;
Type exchange(Type newValue) noexcept:newValue is assigned
to the current object;
bool is_lock_free() const noexept:true is returned, otherwise false.
This member has no memory_order parameter;
Type load() const noexcept:
operator Type() const noexcept:
void store(Type newValue) noexcept:NewValue is assigned to the current object. Note that the standard
assignment operator can also be used.
In addition to the above members, integral atomic types `Integral'
(essentially the atomic variants of all built-in integral types) also offer
the following member functions:
Integral fetch_add(Integral value) noexcept:Value is added to the object's value, and the object's
value at the time of the call is returned;
Integral fetch_sub(Integral value) noexcept:Value is subtracted from the object's value, and the object's
value at the time of the call is returned;
Integral fetch_and(Integral mask) noexcept:bit-and operator is applied to the object's value and
mask, assigning the resulting value to the current object. The
object's value at the time of the call is returned;
Integral fetch_|=(Integral mask) noexcept:bit-or operator is applied to the object's value and mask,
assigning the resulting value to the current object. The object's
value at the time of the call is returned;
Integral fetch_^=(Integral mask) noexcept:bit-xor operator is applied to the object's value and
mask, assigning the resulting value to the current object. The
object's value at the time of the call is returned;
Integral operator++() noexcept:
Integral operator++(int) noexcept:
Integral operator--() noexceptThe prefix decrement operator, returning object's new value;
Integral operator--(int) noexceptThe postfix decrement operator, returning the object's value before it was decremented;
Integral operator+=(Integral value) noexcept:Value is added to the object's current value and the object's
new value is returned;
Integral operator-=(Integral value) noexcept:Value is subtracted from the object's current value and the
object's new value is returned;
Integral operator&=(Integral mask) noexcept:bit-and operator is applied to the object's current value and
mask, assigning the resulting value to the current object. The
object's new value is returned;
Integral operator|=(Integral mask) noexcept:bit-or operator is applied to the object's current value and
mask, assigning the resulting value to the current object. The
object's new value is returned;
Integral operator^=(Integral mask) noexcept:bit-xor operator is applied to the object's current value and
mask, assigning the resulting value to the current object. The
object's new value is returned;
Some of the free member functions have names ending in _explicit. The
_explicit functions define an additional parameter `memory_order
order', which is not available for the non-_explicit functions (e.g.,
atomic_load(atomic<Type> *ptr) and atomic_load_explicit(atomic<Type>
*ptr, memory_order order))
Here are the free functions that are available for all atomic types:
bool
std::atomic_compare_exchange_strong(_explicit)(std::atomic<Type> *ptr,
Type *oldValue, Type newValue) noexept:ptr->compare_exchange_strong(*oldValue, newValue);
bool
std::atomic_compare_exchange_weak(_explicit)(std::atomic<Type> *ptr,
Type *oldValue, Type newValue) noexept:ptr->compare_exchange_weak(*oldValue, newValue);
Type
std::atomic_exchange(_explicit)(std::atomic<Type> *ptr, Type newValue)
noexept:ptr->exchange(newValue);
void std::atomic_init(std::atomic<Type> *ptr, Type
init) noexept:init non-atomically in *ptr. The object pointed to
by ptr must have been default constructed, and as yet no member
functions must have been called for it.
This function has no memory_order parameter;
bool std::atomic_is_lock_free(std::atomic<Type>
const *ptr) noexept:ptr->is_lock_free().
This function has no memory_order parameter;
Type
std::atomic_load(_explicit)(std::atomic<Type> *ptr) noexept:ptr->load();
void
std::atomic_store(_explicit)(std::atomic<Type> *ptr, Type value)
noexept:ptr->store(value).
In addition to the abovementioned free functions atomic<Integral> types
also offer the following free member functions:
Integral
std::atomic_fetch_add(_explicit)(std::atomic<Integral> *ptr, Integral
value) noexcept:ptr->fetch_add(value);
Integral
std::atomic_fetch_sub(_explicit)(std::atomic<Integral> *ptr, Integral
value) noexcept:ptr->fetch_sub(value);
Integral
std::atomic_fetch_and(_explicit)(std::atomic<Integral> *ptr, Integral
mask) noexcept:ptr->fetch_and(value);
Integral
std::atomic_fetch_or(_explicit)(std::atomic<Integral> *ptr, Integral
mask) noexcept:ptr->fetch_or(value);
Integral
std::atomic_fetch_xor(_explicit)(std::atomic<Integral> *ptr, Integral
mask) noexcept:ptr->fetch_xor(mask).
n elements, it works like this:
partition performing the partition is
available). This leaves us with two (possibly empty) sub-arrays: one
to the left of the pivot element, and one to the right of the pivot
element;
To convert this algorithm to a multi-threaded algorithm appears to be be a simple task:
void quicksort(Iterator begin, Iterator end)
{
if (end - begin < 2) // less than 2 elements are left
return; // and we're done
Iter pivot = partition(begin, end); // determine an iterator pointing
// to the pivot element
thread lhs(quicksort, begin, pivot);// start threads on the left-hand
// side sub-arrays
thread rhs(quicksort, pivot + 1, end); // and on the right-hand side
// sub-arrays
lhs.join();
rhs.join(); // and we're done
}
Unfortunately, this translation to a multi-threaded approach won't work for reasonably large arrays because of a phenomenon called overpopulation: more threads are started than the operating system is prepared to give us. In those cases a Resource temporarily unavailable exception is thrown, and the program ends.
Overpopulation can be avoided by using a pool of workers, where each `worker' is a thread, which in this case is responsible for handling one (sub) array, but not for the nested calls. The pool of workers is controlled by a scheduler, receiving the requests to sort sub-arrays, and passing these requests on to the next available worker.
The main data structure of the example program developed in this section is a
queue of std::pairs containing iterators of the array to be sorted
(cf. Figure 26, the sources of the program are found in the C++ Annotations's
yo/threading/examples/multisort directory). Two queues are being used: one
queue is a task-queue, receiving the iterators of sub-arrays to be
partitioned. Instead of immediately launching new threads (the lhs and
rhs threads in the above example), the ranges to be sorted are pushed on
the task-queue. The other queue is the work-queue: elements are moved from the
task-queue to the work-queue, where they will be processed by one of the
worker threads.
The program's main function starts the workforce, reads the data, pushes
the arrays begin and end iterators on the task queue and then starts
the scheduler. Once the scheduler ends the sorted array is displayed:
int main()
{
workForce(); // start the worker threads
readData(); // read the data into vector<int> g_data
g_taskQ.push( // prepare the main task
Pair(g_data.begin(), g_data.end())
);
scheduler(); // sort g_data
display(); // show the sorted elements
}
The workforce consists of a bunch of detached threads. Each thread represents
a worker, implemented in the function void worker. Since the number of
worker threads is fixed, overpopulation doesn't occur. Once the array has been
sorted and the program stops these detached threads simply end:
for (size_t idx = 0; idx != g_sizeofWorkforce; ++idx)
thread(worker).detach();
The scheduler continues for as long as there are sub-arrays to sort. When this is the case the task queue's front element is moved to the work queue. This reduces the work queue's size, and prepares an assignment for the next available worker. The scheduler now waits until a worker is available. Once workers are available one of them is informed of the waiting assignment, and the scheduler waits for the next task:
void scheduler()
{
while (newTask())
{
g_workQ.rawPushFront(g_taskQ);
g_workforce.wait(); // wait for a worker to be available
g_worker.notify_all(); // activate a worker
}
}
The function newTask simply checks whether the task queue is empty. If so,
and none of the workers is currently busy sorting a sub-array then the array
has been sorted, and newTask can return false. When the task queue is
empty but a worker is still busy, it may be that new sub-array dimensions are
going to be placed on the task queue by an active worker. Whenever a worker is
active the Semaphore g_workforce's size is less than the size of the work
force:
bool wip()
{
return g_workforce.size() != g_sizeofWorkforce;
}
bool newTask()
{
bool done;
unique_lock<mutex> lk(g_taskMutex);
while ((done = g_taskQ.empty()) && wip())
g_taskCondition.wait(lk);
return not done;
}
Each detached worker thread performs a continuous loop. In the loop it waits for a notification by the scheduler. Once it receives a notification it retrieves its assignment from the work queue, and partitions the sub-array specified in its assignment. Partitioning may result in new tasks. Once this has been completed the worker has completed its assignment: it increments the available workforce and notifies the scheduler that it should check whether all tasks have been performed:
void worker()
{
while (true)
{
g_worker.wait(); // wait for action
partition(g_workQ.popFront());
g_workforce.notify_all();
lock_guard<mutex> lk(g_taskMutex);
g_taskCondition.notify_one();
}
}
Sub-arrays smaller than two elements need no partitioning. All larger
sub-arrays are partitioned relative to their first element. The
std::partition generic algorithm does this well, but if the pivot is
itself an element of the array to partition then the pivot's eventual location
is undetermined: it may be found anywhere in the series of elements which are
at least equal to the pivot. The two required sub-arrays, however, can easily
be constructed:
std::partition relative to an array's first element,
partitioning the array's remaining elements, returning mid,
pointing to the first element of the series of elements that are at
least as large as the array's first element;
mid - 1
points;
array.begin() to
mid - 1 (elements all smaller than the pivot), and from mid to
array.end() (elements all at least as large as the pivot).
void partition(Pair const &range)
{
if (range.second - range.first < 2)
return;
auto rhsBegin = partition(range.first + 1, range.second,
[=](int value)
{
return value < *range.first;
}
);
auto lhsEnd = rhsBegin - 1;
swap(*range.first, *lhsEnd);
pushTask(range.first, lhsEnd);
pushTask(rhsBegin, range.second);
}
Objects that contain such shared states are called
asynchronous return objects. However,
due to the nature of multi threading, a thread may request the results of an
asynchronous return object before these result are actually available. In
those cases the requesting thread blocks, waiting for the results to become
available. Asynchronous return objects offer wait and get members
which, respectively, wait until the results have become available, and
produce the asynchronous results once they are available. The phrase that
is used to indicate that the results are available is `the shared state has
been made ready'.
Shared states are made ready by asynchronous providers. Asynchronous providers are simply objects or functions providing results to shared states. Making a shared state ready means that an asynchronous provider
wait, to return).
Once a shared state has been made ready it contains a value, object, or exception which can be retrieved by objects having access to the shared state. While code is waiting for a shared state to become ready the value or exception that is going to be stored in the shared state may be computed. When multiple threads try to access the same shared state they must use synchronizing mechanisms (like mutexes, cf. section 20.2) to prevent access-conflicts.
Shared states use reference counting to keep track of the number of asynchronous return objects or asynchronous providers that hold references to them. These return objects and providers may release their references to these shared states (which is called `releasing the shared state). This happens when a return object or provider holds the last reference to the shared state, and the shared state is destroyed.
On the other hand, an asynchronous provider may also abandon its shared state. In that case the provider, in sequence,
std::future_error, holding the error condition
std::broken_promise in its shared state;
Objects of the class std::future (see the next section) are asynchronous
return objects. They can be produced by the std::async (section
20.10) family of functions, and by objects of the classes
std::packaged_task (section 20.11), and std::promise (section
20.12).
join member.
Waiting may be unwelcome: instead of just waiting our thread might also be doing something useful. It might as well pick up the results produced by a sub-thread at some point in the future.
In fact, exchanging data among threads always poses some difficulties, as it
requires shared variables, and the use of locks and mutexes to prevent data
corruption. Rather than waiting and using locks it would be nice if some
asynchronous task could be started, allowing the initiating thread (or even
other threads) to pick up the result at some point in the future, when the
results are needed, without having to worry about data locks or waiting times.
For situations like these C++ provides the class std::future.
Before using the class std::future the <future> header file
must be included.
Objects of the class template std::future harbor the results
produced by asynchronously executed tasks. The class std::future is a
class template. Its template type parameter specifies the type of the result
returned by the asynchronously executed task. This type may be void.
On the other hand, the asynchronously executed task may throw an exception
(ending the task). In that case the future object catches the exception,
and rethrows it once its return value (i.e., the value returned by the
asynchronously executed task) is requested.
In this section the members of the class template future are
described. Future objects are commonly initialized through anonymous
future objects returned by the factory function std::async or by the
get_future members of the classes std::promise, and
std::packaged_task (introduced in upcoming sections). Examples of the use
of std::future objects are provided in those sections.
Some of future's members return a value of the strongly typed
enumeration std::future_status. This enumeration defines
three symbolic constants: future_status::ready, future_status::timeout,
and future_status::deferred.
Error conditions are returned through std::future_error
exceptions. These error conditions are represented by the values of the
strongly typed enumeration std::future_errc (covered in the next section).
The class future itself provides the following constructors:
future():future object that does not
refer to shared results. Its valid member returns false.
future(future &&tmp) noexcept:valid member returns what
tmp.valid() would haved returned prior to the constructor
invocation. After calling the move constructor tmp.valid() returns
false.
future does not offer a copy constructor or an overloaded
assignment operator.
Here are the members of the class std::future:
future &operator=(future &&tmp):tmp
object; following this, tmp.valid() returns false.
std::shared_future<ResultType> share() &&:std::shared_future<ResultType> (see section
20.9). After calling this function, the future's
valid member returns false.
ResultType get():wait (see below) is called. Once wait has returned the
results produced by the associated asynchronous task
are returned. With future<Type> specifications the returned value
is the moved shared value if Type supports move assignment,
otherwise a copy is returned. With future<Type &> specifications
a Type & is returned, with future<void> specifications nothing
is returned. If the shared value is an exception, it is thrown instead
of returned. After calling this member the future object's
valid member returns false.
bool valid() const:true if the (future) object for which valid is
called refers to an object returned by an asynchronous task. If
valid returns false, the future object exists, but in
addition to valid only its destructor and move constructor can
safely be called. When other members are called while valid
returns false a std::future_error exception is
thrown (having the value future_errc::no_state).
void wait() const:
std::future_status wait_for(chrono::duration<Rep, Period> const
&rel_time) const:Rep and Period
from the actually specified duration (cf. section 4.2.2). If
the results contain a deferred function nothing happens. Otherwise
wait_for blocks
until the results are available or until the amount of time
specified by rel_time has expired. Possible return values are:
future_status::deferred if the results contains a
deferred function;
future_status::ready if the results are available;
future_status::timeout if the function is returning because
the amount of time specified by rel_time has expired.
future_status wait_until(chrono::time_point<Clock, Duration> const
&abs_time) const:Clock and
Duration from the actually specified abs_time (cf. section
4.2.4). If the results contain a deferred function nothing
happens. Otherwise wait_until blocks until the results are
available or until the point in time specified by abs_time has
expired. Possible return values are:
future_status::deferred if the results contain a
deferred function;
future_status::ready if the results are available;
future_status::timeout if the function is returning because
the point in time specified by abs_time has expired.
std::future<ResultType> declares the following friends:
std::promise<ResultType>
(sf. section 20.12), and
template<typename Function, typename... Args>
std::future<typename result_of<Function(Args...)>::type>
std::async(std::launch, Function &&fun, Args &&...args);
(cf. section 20.10).
std::future may return errors by throwing
std::future_error exceptions. These error conditions are represented by
the values of the strongly typed enumeration
std::future_errc which defines the following symbolic
constants:
broken_promise
Broken_promiseis thrown when afutureobject was received whose value was never assigned by apromiseorpackaged_task. For example, an object of the classpromise<int>should set the value of thefuture<int>object returned by itsget_futuremember (cf. section 20.12), but if it doesn't do so, then abroken_promiseexception is thrown, as illustrated by the following program:1: std::future<int> fun() 2: { 3: return std::promise<int>().get_future(); 4: } 5: 6: int main() 7: try 8: { 9: fun().get(); 10: } 11: catch (std::exception const &exc) 12: { 13: std::cerr << exc.what() << '\n'; 14: }At line 3 apromiseobject is created, but its value is never set. Consequently, it `breaks its promise' to produce a value: whenmaintries to retrieve its value (in line 9) astd::futue_errorexception is thrown containing thefuture_errc::broken_promisevalue
future_already_retrieved
Future_already_retrievedis thrown when multiple attempts are made to retrieve thefutureobject from, e.g., apromiseorpackaged_taskobject that (eventually) should be ready. For example:1: int main() 2: { 3: std::promise<int> promise; 4: promise.get_future(); 5: promise.get_future(); 6: }Note that after defining thestd::promiseobject in line 3 it has merely been defined: no value is ever assigned to itsfuture. Even though no value is assigned to thefutureobject, it is a valid object. I.e., after some time the future should be ready, and the future'sgetmember should produce a value. Hence, line 4 succeeds, but then, in line 5, the exception is thrown as `the future has already been retrieved'.
promise_already_satisfied
Promise_already_satisfiedis thrown when multiple attempts are made to assign a value to apromiseobject. Assigning a value orexception_ptrto thefutureof apromiseobject may happen only once. For example:1: int main() 2: { 3: std::promise<int> promise; 4: promise.set_value(15); 5: promise.set_value(155); 6: }
no_state
No_stateis thrown when a member function (other thanvalid, see below) of afutureobject is called when itsvalidmember returnsfalse. This happens, e.g., when calling members of a default constructedfutureobject.No_stateis not thrown forfutureobjects returned by theasyncfactory function or returned by theget_futuremembers ofpromiseorpackaged_tasktype of objects. Here is an example:1: int main() 2: { 3: std::future<int> fut; 4: fut.get(); 5: }
The class std::future_error is derived from the class
std::exception, and offers, in addition to the char const *what()
const member also the member std::error_code const &code() const,
returning an std::error_code object associated
with the thrown exception.
std::async) then
the return value of the asynchronously called function becomes available in
its activating thread through a std::future object. The
future object cannot be used by another thread. If this is required (e.g.,
see this chapter's final section) the future object must be converted to a
std::shared_future object.
Before using the class std::shared_future the <future> header file
must be included.
Once a shared_future object is available, its get member (see below)
can repeatedly be called to retrieve the results of the original future
object. This is illustrated by the next small example:
1: int main()
2: {
3: std::promise<int> promise;
4: promise.set_value(15);
5:
6: auto fut = promise.get_future();
7: auto shared1 = fut.share();
8:
9: std::cerr << "Result: " << shared1.get() << "\n"
10: "Result: " << shared1.get() << "\n"
11: "Valid: " << fut.valid() << '\n';
12:
13: auto shared2 = fut.share();
14:
15: std::cerr << "Result: " << shared2.get() << "\n"
16: "Result: " << shared2.get() << '\n';
17: }
In lines 9 and 10 the promise's results are retrieved multiple times,
but having obtained the shared_future in line 7, the original future
object no longer has an associated shared state. Therefore, when another
attempt is made (in line 13) to obtain the shared_future, a no
associated state exception is thrown and the program aborts.
However, multiple copies of shared_future objects may co-exist. When
multiple copies of shared_future objects exist (e.g. in different
threads), the results of the associated asynchronous task are made ready
(become available) at exactly the same moment in time.
The relationship between the classes future and shared_future
resembles the relationship between the classes unique_ptr and
shared_ptr: there can only be one instance of a unique_pointer,
pointing to data, whereas there can be many instances of a shared_pointer,
each pointing to the same data.
The effect of calling any member of a shared_future object for which
valid() == false other than the destructor, the move-assignment operator,
or valid is undefined.
The class shared_future supports the following constructors:
shared_future() noexcept
an emptyshared_futureobject is constructed that does not refer to shared results. After using this constructor the object'svalidmember returnsfalse.
shared_future(shared_future const &other)
ashared_futureobject is constructed that refers to the same results asother(if any). After using this constructor the object'svalidmember returns the same value asother.valid().
shared_future(shared_future<Result> &&tmp) noexcept
Effects: move constructs a shared_future object that refers to the results that were originally referred to bytmp(if any). After using this constructor the object'svalidmember returns the same value astmp.valid()returned prior to the constructor invocation, andtmp.valid()returnsfalse.
shared_future(future<Result> &&tmp) noexcept
Effects: move constructs a shared_future object that refers to the results that were originally referred to bytmp(if any). After using this constructor the object'svalidmember returns the same value astmp.valid()returned prior to the constructor invocation, andtmp.valid()returnsfalse.
The class's destructor destroys the shared_future object for which it is
called. If the object for which the destructor is called is the last
shared_future object, and no std::promise or
std::packaged_task is associated with the results associated
with the current object, then the results are also destroyed.
Here are the members of the class std::shared_future:
shared_future& operator=(shared_future &&tmp):tmp's results to the current
object. After calling the move assignment operator the current
object's valid member returns the same value as tmp.valid()
returned prior to the invocation of the move assignment operator, and
tmp.valid() returns false;
shared_future& operator=(shared_future const &rhs):rhs's results are shared with the current object. After
calling the assignment operator the current object's valid member
returns the same value as tmp.valid();
Result const &shared_future::get() const:shared_future<Result &> and
shared_future<void> are also available). This member waits until
the shared results are available, and subsequently returns Result
const &. Note that access to the data stored in Results, accessed
through get is not synchronized. It is the responsibility of the
programmer to avoid race conditions when accessing Result's
data. If Result holds an exception, it is thrown when get is
called;
bool valid() const:true if the current object refers to shared
results;
void wait() const:
future_status wait_for(const chrono::duration<Rep, Period>& rel_time)
const:Rep and Period normally are derived by the
compiler from the actual rel_time specification.) If the shared
results contain a deferred function (cf. section 20.10) nothing
happens. Otherwise wait_for blocks until the results of the
associated asynchronous task has produced results, or until the
relative time specified by rel_time has expired. The member
returns
future_status::deferred if the shared results contain a
deferred function; future_status::ready if the shared results
are available;
future_status::timeout if the function is returning because
the amount of time specified by rel_time has expired;
future_status wait_until(const chrono::time_point<Clock, Duration>&
abs_time) const:Clock and Duration normally are derived by
the compiler from the actual abs_time specification.) If the
shared results contain a deferred function nothing happens. Otherwise
wait_until blocks until the shared results are available or until
the point in time specified by abs_time has expired. Possible
return values are:
future_status::deferred if the shared results contain a
deferred function;
future_status::ready if the shared results are available;
future_status::timeout if the function is returning because
the point in time specified by abs_time has expired.
std::async is
covered. Async is used to start asynchronous tasks, returning values (or
void) to the calling thread, which is hard to realize merely using the
std::thread class.
Before using the function async the <future> header file must be
included.
When starting a thread using the facilities of the class std::thread the
initiating thread at some point commonly calls the thread's join
method. At that point the thread must have finished or execution blocks until
join returns. While this often is a sensible course of action, it may not
always be: maybe the function implementing the thread has a return value, or
it could throw an exception.
In those cases join cannot be used: if an exception leaves a thread, then
your program ends. Here is an example:
1: void thrower()
2: {
3: throw std::exception();
4: }
5:
6: int main()
7: try
8: {
9: std::thread subThread(thrower);
10: }
11: catch (...)
12: {
13: std::cerr << "Caught exception\n";
14: }
In line 3 thrower throws an exception, leaving the thread. This
exception is not caught by main's try-block (as it is defined in another
thread). As a consequence, the program terminates.
This scenario doesn't occur when std::async is used. Async may start a
new asynchronous task, and the activating thread may retrieve the return value
of the function implementing the asynchronous task or any exception leaving
that function from a std::future object returned by the async
function. Basically, async is called similarly to the way a thread is
started using std::thread: it is passed a function and optionally
arguments which are forwarded to the function.
Although the function implementing the asynchronous task may be passed as
first argument, async's first argument may also be a value of the strongly
typed enumeration std::launch:
enum class launch
{
async,
deferred
};
When passing launch::async the asynchronous task immediately starts;
when passing launch::deferred the asynchronous task is deferred. When
std::launch is not specified the default value launch::async |
launch::deferred is used, giving the implementation freedom of choice,
usually resulting in deferring execution of the asynchronous task.
So, here is the first example again, this time using async to start the
sub-thread:
1: bool fun()
2: {
3: return std::cerr << " hello from fun\n";
4: }
5: int exceptionalFun()
6: {
7: throw std::exception();
8: }
9:
10: int main()
11: try
12: {
13: auto fut1 = std::async(std::launch::async, fun);
14: auto fut2 = std::async(std::launch::async, exceptionalFun);
15:
16: std::cerr << "fun returned " << std::boolalpha << fut1.get() << '\n';
17: std::cerr << "exceptionalFun did not return " << fut2.get() << '\n';
18: }
19: catch (...)
20: {
21: std::cerr << "caught exception thrown by exceptionalFun\n";
22: }
Now the threads immediately start, but although the results are
available around line 13, the thrown exception isn't terminating the
program. The first thread's return value is made available in line 16, the
exception thrown by the second thread is simply caught by main's try-block
(line 19).
The function template async has several overloaded versions:
std::future holding the function's return value or exception
thrown by the function:
template <typename Function, class ...Args>
std::future<
typename std::result_of< Function(Args ...) >::type
> std::async(Function &&fun, Args &&...args);
bit_or
operator) of the enumeration values of the std::launch enumeration:
template <class Function, class ...Args>
std::future<typename std::result_of<Function(Args ...)>::type>
std::async(std::launch policy, Function &&fun, Args &&...args);
std::launch values, the second
argument may also be the address of a member function. In that case the
(required) third argument is an object (or a pointer to an object) of that
member function's class. Any remaining arguments are passed to the member
function (see also the remarks below).
async all arguments except for the std::launch
argument must be references, pointers or move-constructible objects:
async function template then
copy construction is used to construct a copy of the argument which is
then forwarded to the thread-launcher.
async function template
then move construction is used to forward the anonymous object to the
thread launcher.
get member is
called).
Because of the default std::launch::deferred | std::launch::async argument
used by the basic async call it is likely that the function which is
passed to async doesn't immediately start. The launch::deferred policy
allows the implementor to defer its execution until the program explicitly
asks for the function's results. Consider the following program:
1: void fun()
2: {
3: std::cerr << " hello from fun\n";
4: }
5:
6: std::future<void> asyncCall(char const *label)
7: {
8: std::cerr << label << " async call starts\n";
9: auto ret = std::async(fun);
10: std::cerr << label << " async call ends\n";
11: return ret;
12: }
13:
14: int main()
15: {
16: asyncCall("First");
17: asyncCall("Second");
18: }
Although async is called in line 9, the program's output may not show
fun's output line when it is run. This is a result of the (default) use
of lauch::deferred: the system simply defers fun's execution until
requested, which doesn't happen. But the future object that's returned by
async has a member wait. Once wait returns the shared state must
be available. In other words: fun must have finished. Here is what happens
when after line 9 the line ret.wait() is inserted:
First async call starts
hello from fun
First async call ends
Second async call starts
hello from fun
Second async call ends
Actually, evaluation of fun can be requested at the point where we
need its results, maybe even after calling asyncCall, as shown in the next
example:
1: int main()
2: {
3: auto ret1 = asyncCall("First");
4: auto ret2 = asyncCall("Second");
5:
6: ret1.get();
7: ret2.get();
8: }
Here the ret1 and ret2 std::future objects are created, but their
fun functions aren't evaluated yet. Evaluation occurs at lines 6 and 7,
resulting in the following output:
First async call starts
First async call ends
Second async call starts
Second async call ends
hello from fun
hello from fun
The std::async function template is used to start a thread, making its
results available to the calling thread. On the other hand, we may only be
able to prepare (package) a task (a thread), but may have to leave the
completion of the task to another thread. Scenarios like this are realized
through objects of the class std::packaged_task, which is the topic of the
next section.
std::packaged_task allows a program to
`package' a function or functor and pass the package to a thread for further
processing. The processing thread then calls the packaged function, passing it
its arguments (if any). After completing the function the packaged_task's
future is ready, allowing the program to retrieve the results produced by
the function. Thus, functions and the results of function calls can be
transferred between threads.
Before using the class template packaged_task the <future> header file
must be included.
Before describing the class's interface, let's first look at an example to get
an idea about how a packaged_task can be used. Remember that the essence
of packaged_task is that part of your program prepares (packages) a task
for another thread to complete, and that the program at some point needs the
result of the completed task.
To clarify what's happening here, let's first look at a real-life
analogon. Every now and then I make an appointment with my garage to have my
car serviced. The `package' in this case are the details about my car: its
make and type determine the kind of actions my garage performs when servicing
it. My neighbor also has a car, which also needs to be serviced every now and
then. This also results in a `package' for the garage. At the appropriate time
me and my neighbor take our cars to the garage (i.e., the packages are passed
to another thread). The garage services the cars (i.e., calls the functions
stored in the packaged_tasks [note that the tasks differ, depending on the
types of the cars]), and performs some actions that are associated with it
(e.g., registering that my or my neighbor's car has been serviced, or order
replacement parts). In the meantime my neighbor and I perform our own
businesses (the program continues while a separate thread runs as well). But
by the end of the day we'd like to use our cars again (i.e., get the results
associated with the packaged_task). A common result in this example is the
garage's bill, which we have to pay (the program obtains the
packaged_task's results).
Here is a little C++ program illustrating the use of a packaged_task
(assuming the required headers and using namespace std have been
specified):
1: mutex carDetailsMutex;
2: condition_variable condition;
3: string carDetails;
4: packaged_task<size_t (std::string const &)> serviceTask;
5:
6: size_t volkswagen(string const &type)
7: {
8: cout << "performing maintenance by the book for a " << type << '\n';
9: return type.size() * 75; // the size of the bill
10: }
11:
12: size_t peugeot(string const &type)
13: {
14: cout << "performing quick and dirty maintenance for a " << type << '\n';
15: return type.size() * 50; // the size of the bill
16: }
17:
18: void garage()
19: {
20: while (true)
21: {
22: unique_lock<mutex> lk(carDetailsMutex);
23: while (carDetails.empty())
24: condition.wait(lk);
25:
26: cout << "servicing a " << carDetails << '\n';
27: serviceTask(carDetails);
28: carDetails.clear();
29: }
30: }
31:
32: int main()
33: {
34: thread(garage).detach();
35:
36: while (true)
37: {
38: string car;
39: if (not getline(cin, car) || car.empty())
40: break;
41: {
42: lock_guard<mutex> lk(carDetailsMutex);
43: carDetails = car;
44: }
45: serviceTask = packaged_task<size_t (string const &)>(
46: car[0] == 'v' ? volkswagen : peugeot
47: );
48: auto bill = serviceTask.get_future();
49: condition.notify_one();
50: cout << "Bill for servicing a " << car <<
51: ": EUR " << bill.get() << '\n';
52: }
53: }
packaged_task: serviceTask is initialized with a
function (or functor) expecting a string, returning a size_t;
volkswagen and
peugeot represent the tasks to perform when cars of the provided
types come in for service; presumably they return the bill.
void garage, defining the actions
performed by the garage when cars come in for service. These actions
are performed by a separate detached thread, starting in line 34. In a
continuous loop it waits until it obtains a lock on the
carDetailsMutex and carDetails is no longer empty. Then, at
line 27, it passes carDetails to the packaged_task
`serviceTask'. By itself this is not identical to calling the
packaged_task's function, but eventually its function will be
called. At this point the packaged_task receives its function's
arguments, which it eventually will forward to its configured
function. Finally, at line 28 it clears carDetails, thus preparing
itself for the next request.
main:
garage is started.
volkswagen or peugeot), and the packaged_task, provided with
the right servicing function, is constructed
next (line 45).
future, are
retrieved. Although at this point the future might not be
ready, the future object itself is, and it is simply
returned as the bill.
bill.get()
in line 51. If, by this time, the car is still being serviced, the
bill isn't ready yet, and bill.get() blocks until it is, and
the bill for servicing a car is shown.
packaged_task,
let's have a look at its interface. Note that the class packaged_task is a
class template: its template type parameter specifies the prototype of a
function or function object implementing the task performed by the
packaged_task object.
Constructors and destructor:
packaged_task() noexcept:packaged_task object which is
not associated with a function or shared state;
explicit packaged_task<ReturnType(Args...)> task(fun):packaged_task is constructed for a function or functor fun
expecting arguments of types Args..., and returning a value of
type ReturnType. The packaged_task class template specifies
ReturnType (Args...) as its template type parameter. The
constructed object contains a shared state, and a (move constructed)
copy of function.
Optionally an Allocator may be specified as second template type
parameter, in which case the first two arguments are
std::allocator_arg_t, Allocator const
&alloc. The type std::allocator_arg_t is a type introduced to
disambiguate constructor selections, and can simply be specified as
std::allocator_arg_t().
This constructor may throw a std::bad_alloc exception or
exceptions thrown by function's copy or move constructors.
packaged_task(packaged_task &&tmp) noexcept:tmp to
the newly constructed object, removing the shared state from tmp.
~packaged_task():Member functions:
future<ReturnType> get_future():std::future object is returned holding the results of the
separately executed thread. When get_future is incorrectly called
a future_error exception is thrown, containing one of the
following values:
future_already_retrieved if get_future was already called on a
packaged_task object containing the same shared state as the
current object;
no_state if the current object has no shared state.
futures that share the object's shared state may access
the result returned by the object's task.
void make_ready_at_thread_exit(Args... args):void operator()(Args... args) (see below) when the current
thread exits, once all objects of thread storage duration associated
with the current thread have been destroyed.
packaged_task &operator=(packaged_task &&tmp):tmp are swapped;
void operator()(Args... args):args arguments are forwarded to the current object's
stored task. When the stored task returns its return value is stored
in the current object's shared state. Otherwise any exception thrown
by the task is stored in the object's shared state. Following this the
object's shared state is made ready, and any threads blocked in a
function waiting for the object's shared state to become ready are
unblocked. A future_error exception is thrown upon error,
containing
promise_already_satisfied if the shared state has already been
made ready;
no_state if the current object does not have any shared state.
(shared_)future object that provides access to the
packaged_task's results.
void reset():packaged_task(std::move(funct)), where funct is the
object's stored task. This member may throw the following exceptions:
bad_alloc if memory for the new shared state could not be
allocated;
future_error with a no_state error condition if the current
object contains no shared state.
void swap(packaged_task &other) noexcept:
bool valid() const noexcept:true if the current object contains a shared state,
otherwise false is returned;
The following non-member (free) function operating on packaged_task
objects is available:
void swap(packaged_task<ReturnType(Args...)> &lhs,
packaged_task<ReturnType(Args...)> &rhs) noexcept
Calls lhs.swap(rhs)
std::packaged_task and std::async the class template
std::promise can be used to obtain the results from a
separate thread.
Before using the class template promise the <future> header file
must be included.
A promise is used to obtain the results from another thread without
further synchronization requirements. Consider the following program:
void compute(int *ret)
{
*ret = 9;
}
int main()
{
int ret = 0;
std::thread(compute, &ret).detach();
cout << ret << '\n';
}
Chances are that this program shows the value 0: the cout statement has
already been executed before the detached thread has had a chance to complete
its work. In this example that problem can easily be solved by using a
non-detached thread, and using the thread's join member, but when multiple
threads are used that requires named threads and as many join
calls. Instead, using a promise might be preferred:
1: void compute(promise<int> &ref)
2: {
3: ref.set_value(9);
4: }
5:
6: int main()
7: {
8: std::promise<int> prom;
9: std::thread(compute, ref(prom)).detach();
10:
11: cout << prom.get_future().get() << '\n';
12: }
This example also uses a detached thread, but its results are kept for
future reference in a promise object, instead of directly being assigned
to a final destination variable. The promise object contains a future
object holding the computed value. The future's get member blocks until
the future has been made ready, at which point the result becomes
available. By then the detached thread may or may not yet have been
completed. If it already completed its work then get immediately returns,
otherwise there will be a slight delay.
Promises are useful when implementing a multi threaded version of some
algorithm without having to use additional synchronization statements. As an
example consider matrix multiplications. Each element of the resulting
product matrix is computed as the inner product of two vectors: the inner
product of a row of the left-hand matrix operand and a column of the
right-hand matrix operand becomes element [row][column] of the resulting
matrix. Since each element of the resulting matrix can independently be
computed from the other elements, a multi threaded implementation is well
possible. In the following example the function innerProduct (lines 4..11)
leaves its result in a promise object:
1: int m1[2][2] = {{1, 2}, {3, 4}};
2: int m2[2][2] = {{3, 4}, {5, 6}};
3:
4: void innerProduct(promise<int> &ref, int row, int col)
5: {
6: int sum = 0;
7: for (int idx = 0; idx != 2; ++idx)
8: sum += m1[row][idx] * m2[idx][col];
9:
10: ref.set_value(sum);
11: }
12:
13: int main()
14: {
15: promise<int> result[2][2];
16:
17: for (int row = 0; row != 2; ++row)
18: {
19: for (int col = 0; col != 2; ++col)
20: thread(innerProduct, ref(result[row][col]), row, col).detach();
21: }
22:
23: for (int row = 0; row != 2; ++row)
24: {
25: for (int col = 0; col != 2; ++col)
26: cout << setw(3) << result[row][col].get_future().get();
27: cout << '\n';
28: }
29: }
Each inner product is computed by a separate (anonymous and detached)
thread (lines 17..21), which starts as soon as the run-time system allows it
to start. By the time the threads have finished the resulting inner products
can be retrieved from the promises' futures. Since futures' get members
block until their results are actually available, the resulting matrix can
simply be displayed by calling those members in sequence (lines 23..28).
So, a promise allows us to use a thread to compute a value (or
exception, see below), which value may then be collected by another thread at
some future point in time. The promise remains available, and as a consequence
further synchronization of the threads and the program starting the threads is
not necessary. When the promise object contains an exception, rather than a
value, its future's get member rethrows the stored exception.
Here is the class promise's interface. Note that the class promise is
a class template: its template type parameter ReturnType specifies the
template type parameter of the std::future that can be retrieved from it.
Constructors and destructor:
promise():promise object containing a
shared state. The shared state may be returned by the member
get_future (see below), but that future has not yet been made
ready;
promise(promise &&tmp) noexcept:promise object, transferring
the ownership of tmp's shared state to the newly constructed
object. After the object has been constructed, tmp no longer
contains a shared state;
~promise():Member functions:
std::future<ReturnType> get_future():std::future object sharing the current object's shared state is
returned. A future_error exception is thrown upon error,
containing
future_already_retrieved if get_future was already called on a
packaged_task object containing the same shared state as the
current object;
no_state if the current object has no shared state.
futures that share the object's shared state may
access the result returned by the object's task;
promise &operator=(promise &&rhs) noexcept:tmp are swapped;
void promise<void>::set_value():set_value member's description;
void set_value(ReturnType &&value):set_value member's description;
void set_value(ReturnType const &value):
void set_value(ReturnType &value):value) is atomically stored in the shared state,
which is then also made ready. A future_error exception is thrown
upon error, containing
promise_already_satisfied if the shared state has already been
made ready;
no_state if the current object does not have any shared state.
value's move or copy
constructor may be thrown;
void set_exception(std::exception_ptr obj):Exception_ptr obj (cf. section 10.9.4) is atomically stored
in the shared state, making that state ready. A future_error
exception is thrown upon error, containing
promise_already_satisfied if the shared state has already been
made ready;
no_state if the current object does not have any shared state;
void set_exception_at_thread_exit(exception_ptr ptr):ptr is stored in the shared state without
immediately making that state ready. The state becomes ready when the
current thread exits, once all objects of thread storage duration
which are associated with the ending thread have been destroyed. A
future_error exception is thrown upon error, containing
promise_already_satisfied if the shared state has already been
made ready;
no_state if the current object does not have any shared state;
void set_value_at_thread_exit():set_value_at_thread_exit member's
description;
void set_value_at_thread_exit(ReturnType &&value):set_value_at_thread_exit member's
description;
void set_value_at_thread_exit(ReturnType const &value):set_value_at_thread_exit member's
description;
void set_value_at_thread_exit(ReturnType &value):value in the shared state without immediately making that
state ready. The state becomes ready when the current thread exits,
once all objects of thread storage duration which are associated with
the ending thread have been destroyed. A future_error exception
is thrown upon error, containing
promise_already_satisfied if the shared state has already been
made ready;
no_state if the current object does not have any shared state;
void swap(promise& other) noexcept:other are
exchanged.
The following non-member (free) function operating on promise objects is
available:
void swap(promise<ReturnType> &lhs, promise<ReturnType> &rhs)
noexcept:lhs.swap(rhs)
packaged_tasks.
Like the multi-threaded quicksort example a worker pool is used. However, in this example the workers in fact do not know what their task is. In the current example the tasks happens to be identical, but different tasks might as well have been used, without having to update the workers.
The program uses a class Task containing a command-specification
(d_command), and a task specification (d_task) (cf. Figure 27), the
sources of the program are found in the
yo/threading/examples/multicompile directory of the C++ Annotations.
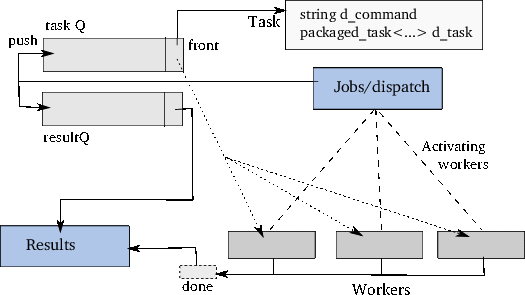
In this program main starts by firing up its workforce in a series of
threads. Following this, the compilation jobs are prepared and pushed on a
task-queue by jobs, where they're retrieved from by the workers. Once
the compilations have been completed (i.e., after the worker threads have
joined the main thread), the results of the compilation jobs are handled by
results:
int main()
{
workforce(); // start the worker threads
jobs(); // prepare the jobs: push all tasks on the
// taskQ
for (thread &thr: g_thread) // wait for the workers to end
thr.join();
results(); // show the results
}
The jobs function receives the names of the files to compile from the
nextCommand function, which ignores empty lines and returns non-empty
lines. Eventually nextCommand returns an empty line once all lines of the
standard input stream have been read:
string nextCommand()
{
string ret;
while (true)
{
if (not getline(cin, ret)) // no more lines
break;
if (not ret.empty()) // ready once there's line content.
break;
}
return ret;
}
With non-empty lines jobs waits for an available worker using (line 12)
the g_dispatcher semaphore. Initialized to the size of the work force, it
is reduced by an active worker, and incremented by workers who have completed
their tasks. If a compilation fails, then g_done is set to true and no
additional compilations are performed (lines 14, 15). While jobs receives
the names of the files to compile, workers may detect compilation errors. If
so, the workers set variable g_done to true. Once the job
function's while loop ends the workers are notified once again (line 24),
who will then, because there's no task to perform anymore, end their threads
1: void jobs()
2: {
3: while (true)
4: {
5: string line = nextCommand();
6: if (line.empty()) // no command? jobs() done.
7: {
8: g_done = true;
9: break;
10: }
11:
12: g_dispatcher.wait(); // wait for an available worker
13:
14: if (g_done.load()) // if a worker found an error
15: break; // then quit anyway
16:
17: newTask(line); // push a new task (and its
18: // results)
19:
20: g_worker.notify_all(); // inform the workers: job is
21: // available
22: }
23:
24: g_worker.notify_all(); // end the workers at an empty Q
25: }
The function newTask prepares the program for the next task. First a
Task object is constructed. Task contains the name of the file to
compile, and a packaged_task. It encapsulates all activities that are
associated with a packaged_task. Here is its (in-class) definition:
1: using PackagedTask = packaged_task<Result (string const &fname)>;
2:
3: class Task
4: {
5: string d_command;
6: PackagedTask d_task;
7:
8: public:
9: Task() = default;
10:
11: Task(string const &command, PackagedTask &&tmp)
12: :
13: d_command(command),
14: d_task(move(tmp))
15: {}
16:
17: void operator()()
18: {
19: d_task(d_command);
20: }
21:
22: shared_future<Result> result()
23: {
24: return d_task.get_future().share();
25: }
26: };
Note (lines 22-25) that result returns a shared_future. Since the
dispatcher runs in a different thread than the one processing the results, the
futures created by the dispatcher must be shared with the futures
required by the function processing the results. Hence the shared_futures
returned by Task::result.
Once a Task object has been constructed its shared_future object is
pushed on the result queue. Although the actual results aren't available by
this time, the result function is eventually called to process the results
that were pushed on the result-queue. Additionally, the Task itself is
pushed on a task queue, and it will be retrieved by a worker:
class Task
{
string d_command;
PackagedTask d_task;
public:
Task() = default;
Task(string const &command, PackagedTask &&tmp);
void operator()();
shared_future<Result> result();
};
void pushResultQ(shared_future<Result> const &sharedResult)
{
lock_guard<mutex> lk(g_resultQMutex);
g_resultQ.push(sharedResult);
}
The workers have a simple task: wait for the next task, then retrieve it from
the task queue, and complete that task. Whatever happens inside the tasks
themselves is of no concern to the worker. Also, when notified (normally by
the jobs function) that there's a task waiting it'll execute that
task. However, at the end, once all tasks have been pushed on the task queue,
jobs once again notifies the workers. In that case the task queue is
empty, and the worker function ends. But just before that it notifies its
fellow workers, which in turn end, thus ending all worker threads, allowing
them to join the main-thread:
void worker()
{
Task task;
while (true)
{
g_worker.wait(); // wait for an available task
if (g_taskQ.empty()) // no task? then done
break;
g_taskQ.popFront(task);
g_dispatcher.notify_all(); // notify the dispatcher that
// another task can be pushed
task();
}
g_worker.notify_all(); // no more tasks: notify the other
} // workers.
This completes the description of how tasks are handled.
The task itself are now described. In the current program C++ source files
are compiled. The compilation command is passed to the constructor of a
CmdFork object, which starts the compiler as a child process. The result
of the compilation is retrieved via its childExit member (returning the
compiler's exit code) and childOutput member (returning any textual output
produced by the compiler). If compilation fails, the exit value won't be
zero. In this case no further compilation tasks will be issued as g_done
is set to true (lines 11 and 12; the implementation of the class
CmdFork is available from the C++ Annotations'
yo/threading/examples/cmdfork directory). Here is the function
compile:
1: Result compile(string const &line)
2: {
3: string command("/usr/bin/g++ -Wall -c " + line);
4:
5: CmdFork cmdFork(command);
6: cmdFork.fork();
7:
8: Result ret {cmdFork.childExit() == 0,
9: line + "\n" + cmdFork.childOutput()};
10:
11: if (not ret.ok)
12: g_done = true;
13:
14: return ret;
15: }
The results function continues for as long as newResults indicates
that results are available. By design the program will show all available
successfully completed compilations, and (if several workers encountered
compilation errors) only the compiler's output of the first
compilation error is displayed. All available successfully completed
compilations meaning that, in case of a compilation error, the source files
that were successfully compiled by the currently active work force are listed,
but remaining source files are not processed anymore:
void results()
{
Result result;
string errorDisplay;
while (newResult(result))
{
if (result.ok)
cerr << result.display;
else if (errorDisplay.empty())
errorDisplay = result.display; // remember the output of
} // the first compilation error
if (not errorDisplay.empty()) // which is displayed at the end
cerr << errorDisplay;
}
The function newResult controls results' while-loop. It returns
true when as long as the result queue isn't empty, in which case the
queue's front element is stored at the external Result object, and the
queue's front element is removed from the queue:
bool newResult(Result &result)
{
if (g_resultQ.empty())
return false;
result = g_resultQ.front().get();
g_resultQ.pop();
return true;
}
Transactional memory is used to simplify shared data access in multithreaded programs. The benefits of transactional memory is best illustrated by a small program. Consider a situation where threads need to write information to a file. A plain example of such a program would be:
void fun(int value)
{
for (size_t rept = 0; rept != 10; ++rept)
{
this_thread::sleep_for(chrono::seconds(1));
cout << "fun " << value << '\n';
}
}
int main()
{
thread thr{ fun, 1 };
fun(2);
thr.join();
}
When this program is run the fun 1 and fun 2 messages are
intermixed. To prevent this we traditionally define a mutex, lock it,
write the message, and release the lock:
void fun(int value)
{
static mutex guard;
for (size_t rept = 0; rept != 10; ++rept)
{
this_thread::sleep_for(chrono::seconds(1));
guard.lock();
cout << "fun " << value << '\n';
guard.unlock();
}
};
Transactional memory handles the locking for us. Transactional memory is used
when statements are embedded in a synchronized block. The function
fun, using transactional memory, looks like this:
void fun(int value)
{
for (size_t rept = 0; rept != 10; ++rept)
{
this_thread::sleep_for(chrono::seconds(1));
synchronized
{
cout << "fun " << value << '\n';
}
}
};
To compile source files using transactional memory the g++ compiler
option -fgnu-tm must be specified.
The code inside a synchronized block is executed as a single, as if the block was protected by a mutex. Different from using mutexes transactional memory is implemented in software instead of using hardware-facilities.
Considering how easy it is to use transactional memory compared to using
the mutex-based locking mechanism using transactional memory appears
too good to be true. And in a sense it is. When encountering a synchronized
block the thread unconditionally executes the block's statements. At the same
time it keeps a detailed log of all its actions. Once the statements have been
completed the thread checks whether another thread didn't start executing the
block just before it. If so, it reverses its actions, using the synchronized
block's log. The implication of this should be clear: there's at least the
overhead of maintaining the log, and if another thread started executing
the synchronized block before the current thread then there's the additional
overhead of reverting its actions and to try again.
The advantages of transactional memory should also be clear: the
programmers no longer is responsible for correctly controlling access to
shared memory; risks of encountering deadlocks have disappeared as has all
adminstrative overhead of defining mutexes, locking and unlocking. Especially
for inherently slow operations like writing to files transactional memory can
greatly simplify parts of your code. Consider a std::stack. Its
top-element can be inspected but its pop member does not return the
topmost element. To retrieve the top element and then maybe remove it
traditionally requires a mutex lock surrounding determining the stack's size,
and if empty, release the lock and wait. If not empty then retrieve its
topmost element, followed by removing it from the stack. Using a transactional
memory we get something as simple as:
bool retrieve(stack<Item> &itemStack, Item &item)
{
synchronized
{
if (itemStack.empty())
return false;
item = std::move(itemStack.top());
itemStack.pop();
return true;
}
}
Variants of synchronized are:
atomic_noexcept: the statements inside its compound statement may not
throw exceptions. If they do, std::abort is called. If the earlier
fun function specifies atomic_noexcept instead of
synchronized the compiler generates and error about the use of the
insertion operator, from which an exception may be thrown.
atomic_cancel: not yet supported by g++. If an
exception other than (std::) bad_alloc, bad_array_new_length,
bad_cast, bad_typeid, bad_exception, exception, tx_exception<Type> is
thrown std::abort is called. If an acceptable exception is thrown,
then the statements executed so far are undone.
atomic_commit: if an exception is thrown from its compound statement
all thus far executed statements are kept (i.e., not undone).
Recently the class std::osyncstream was added to the language, allowing
multi threaded programs allowing threads to write information block-wise to a
common stream without having to define separate streams receiving the
thread-specific information, eventually copying those streams to the
destination stream. Before using osyncstream objects the <syncstream>
header file must be included.
The osyncstream class publicly inherits from std::ostream,
initializing the ostream base class with a std::syncbuf stream buffer
(described in the next section), which performs the actual synchronization.
Information written to osyncstream objects can explicitly be copied to a
destination ostream, or is automatically copied to the destination
ostream by the osyncstream's destructor. Each thread may construct its
own osyncstream object, handling the block-wise copying of the
information it receives to the destination stream.
Constructors
osyncstream{ostream &out} constructs an osyncstream object
eventually writing the information it receives to out. Below,
out is called the destination stream;
osyncstream{osyncstream &&tmp} the move constructor is available;
The default- and copy-constructors are not available.
Member functions
In addition to the members inherited from std::ostream (like the
rdbuf member returing a pointer to the object's syncbuf (described in
the next section)) the class osyncstream offers these members:
get_wrapped, returning a pointer to the destination stream's stream
buffer;
emit, copies the received information as a block to the destination
stream.
The following program illustrates how osyncstream objects can be used.
1: #include <iostream>
2: #include <syncstream>
3: #include <string>
4: #include <thread>
5:
6: using namespace std;
7:
8: void fun(char const *label, size_t count)
9: {
10: osyncstream out(cout);
11:
12: for (size_t idx = 0; idx != count; ++idx)
13: {
14: this_thread::sleep_for(1s);
15: out << label << ": " << idx << " running...\n";
16: }
17: out << label << " ends\n";
18: }
19:
20: int main(int argc, char **argv)
21: {
22: cout << "the 1st arg specifies the #iterators "
23: "using 3 iterations by default\n";
24:
25: size_t count = argc > 1 ? stoul(argv[1]) : 3;
26:
27: thread thr1{ fun, "first", count };
28: thread thr2{ fun, "second", count };
29:
30: thr1.join();
31: thr2.join();
32: }
fun (line 8) is called by main from two threads
(lines 27, 28);
osyncstream out and, using short one-second pauses,
writes some lines of text to out (lines 14, 15);
fun the local out content is written
as a block to cout (line 18). Writing out's content to
cout can also explicitly be requested by calling out.emit().
osyncstream stream in fact is only a wrapper of ostream, using a
syncbuf as its stream buffer. The std::syncbuf handles the actual
synchronization. In order to use the syncbuf stream buffer the
<syncstream> header file must be included.
A syncbuf stream buffer collects the information it receives from an
ostream in an internal buffer, and its destructor and emit member
flush its buffer as a block to its destination stream.
Constructors
syncbuf(), the default constructor, constructs a syncbuf object
with its emit-on-sync policy (see below) set to false;
explicit syncbuf(streambuf *destbuf) constructs a std::syncbuf
with its emit-on-sync policy set to false, using destbuf as
the destination stream's streambuf;
syncbuf(syncbuf &&rhs), the move constructor, moves the content of
rhs to the constructed syncbuf.
Member functions
In addition to the members inherited from std::streambuf the class
syncbuf offers these members:
get_wrapped, returning a pointer to the destination stream's stream
buffer;
emit, copies the received information as a block to the destination
stream;
void set_emit_on_sync(bool how) changes the
current emit-on-sync policy. By default how == false flushing its
internal buffer to the destination's stream buffer. When how ==
true the internal buffer is always immediately flushed;
results processes the queued results by showing the
names of the successfully compiled source files, and (if a compilation failed)
the name and error messages of the first source whose compilation failed.
The results-queue was used to store the results in a retrievable data structure, using a mutex to ensure that the workers cannot simultaneously push results on the results-queue.
Using osyncstream objects the results-queue and its mutexed protection
scheme is no longer required (the sources of the modified program are
available in the C++ Annotations' directory
yo/threading/examples/osyncmulticompile).
Instead of using a results-queue the program uses a single destination stream
fstream g_out{ "/tmp/out", ios::trunc | ios::in | ios::out }, and its
compile function defines a local a osyncstream object, ensuring that
its output is sent as a block to g_out:
1: void compile(string const &line)
2: {
3: if (g_done.load())
4: return;
5:
6: string command("/usr/bin/g++ -Wall -c " + line);
7:
8: CmdFork cmdFork(command);
9: cmdFork.fork();
10:
11: int exitValue = cmdFork.childExit();
12:
13: osyncstream out(g_out);
14: out << exitValue << ' ' << line << '\n';
15:
16: if (exitValue != 0)
17: {
18: out << cmdFork.childOutput() << '\n' << g_marker << '\n';
19: g_done = true;
20: }
21: // out.emit(); // handled by out's destructor
22: }
osyncstream out object is defined, and the results
of the compilation are written to out at lines 14 and 18;
out;
out terminated by a marker,
used by results (see below), to recognize the end of the error
messages.
Since the results of the compilation are no longer transferred to another
thread, there's no need for defining a shared_future<Result>. In fact,
since compile handles the results of a compilation itself, it defines
return type void and the packaged_task itself doesn't return anything
either. Therefore the class Task doesn't need a result() member
anymore. Instead, its function-call operator, having completed its task, calls
the task's get_future so exceptions that might have been generated by
the packaged_tasks are properly retrieved. Here's the simplified class
Task:
using PackagedTask = packaged_task<void (string const &fname)>;
class Task
{
string d_command;
PackagedTask d_task;
public:
Task() = default;
Task(string const &command, PackagedTask &&tmp)
:
d_command(command),
d_task(move(tmp))
{}
void operator()()
{
d_task(d_command);
d_task.get_future(); // handles potential exceptions
}
};
At the end of main the function results is called:
1: void results()
2: {
3: g_out.seekg(0);
4:
5: int value;
6: string line;
7: string errorDisplay;
8:
9: while (g_out >> value >> line) // process g_out's content
10: {
11: g_out.ignore(100, '\n');
12:
13: if (value == 0) // no error: show the source file
14: {
15: cerr << line << '\n';
16: continue;
17: }
18: // at compilation errors:
19: if (not errorDisplay.empty()) // after the 1st error: skip
20: {
21: do
22: {
23: getline(g_out, line);
24: }
25: while (line != g_marker);
26:
27: continue;
28: }
29: // first compilation error:
30: errorDisplay = line + '\n'; // keep the the name of the source
31: while (true) // and its error messages
32: {
33: getline(g_out, line);
34:
35: if (line == g_marker)
36: break;
37:
38: errorDisplay += line + '\n';
39: }
40: }
41:
42: cerr << errorDisplay; // eventually insert the error-info
43: } // (if any)
while condition at line 9.
errorDisplay (lines 30 thru 39).
g_out has completely been read errorDisplay is displayed
(line 42), which is either empty or contains the error messages of the
first encountered compilation failure.