Vehicle *vp, points to a Car object Car's speed or
brandName members can't be used.
In the previous chapter two fundamental ways classes may be related to each other were discussed: a class may be implemented-in-terms-of another class and it can be stated that a derived class is-a base class. The former relationship is usually implemented using composition, the latter is usually implemented using a special form of inheritance, called polymorphism, the topic of this chapter.
An is-a relationship between classes allows us to apply the
Liskov Substitution Principle (LSP) according to which a derived
class object may be passed to and used by code expecting a pointer or
reference to a base class object. In the C++ Annotations so far the LSP has been
applied many times. Every time an ostringstream, ofstream or fstream
was passed to functions expecting an ostream we've been applying this
principle. In this chapter we'll discover how to design our own classes
accordingly.
LSP is implemented using a technique called polymorphism: although a base
class pointer is used it performs actions defined in the (derived) class
of the object it actually points to. So, a Vehicle *vp might behave like
a Car * when pointing to a Car (In one of the StarTrek
movies, Capt. Kirk was in trouble, as usual. He met an extremely beautiful
lady who, however, later on changed into a hideous troll. Kirk was quite
surprised, but the lady told him: ``Didn't you know I am a polymorph?'').
Polymorphism is implemented using a feature called late binding. It's called that way because the decision which function to call (a base class function or a function of a derived class) cannot be made at compile-time, but is postponed until the program is actually executed: only then it is determined which member function will actually be called.
In C++ late binding is not the default way functions are called. By default static binding (or early binding) is used. With static binding the functions that are called are determined by the compiler, merely using the class types of objects, object pointers or object references.
Late binding is an inherently different (and slightly slower) process as it is decided at run-time, rather than at compile-time what function is going to be called. As C++ supports both late- and early-binding C++ programmers are offered an option as to what kind of binding to use. Choices can be optimized to the situations at hand. Many other languages offering object oriented facilities (e.g., Java) only or by default offer late binding. C++ programmers should be keenly aware of this. Expecting early binding and getting late binding may easily produce nasty bugs.
Let's look at a simple example to start appreciating the differences between late and early binding. The example merely illustrates. Explanations of why things are as shown are shortly provided.
Consider the following little program:
#include <iostream>
using namespace std;
class Base
{
protected:
void hello()
{
cout << "base hello\n";
}
public:
void process()
{
hello();
}
};
class Derived: public Base
{
protected:
void hello()
{
cout << "derived hello\n";
}
};
int main()
{
Derived derived;
derived.process();
}
The important characteristic of the above program is the Base::process
function, calling hello. As process is the only member that is defined
in the public interface it is the only member that can be called by code not
belonging to the two classes. The class Derived, derived from Base
clearly inherits Base's interface and so process is also available in
Derived. So the Derived object in main is able to call
process, but not hello.
So far, so good. Nothing new, all this was covered in the previous
chapter. One may wonder why Derived was defined at all. It was
presumably defined to create an implementation of hello that's appropriate
for Derived but differing from Base::hello's
implementation. Derived's author's reasoning was as follows: Base's
implementation of hello is not appropriate; a Derived class object can
remedy that by providing an appropriate implementation. Furthermore our author
reasoned:
``since the type of an object determines the interface that is used,processmust callDerived::helloashellois called viaprocessfrom aDerivedclass object''.
Unfortunately our author's reasoning is flawed, due to static binding. When
Base::process was compiled static binding caused the compiler to bind
the hello call to Base::hello().
The author intended to create a Derived class that is-a Base
class. That only partially succeeded: Base's interface was inherited, but
after that Derived has relinquished all control over what happens. Once
we're in process we're only able to see Base's member
implementations. Polymorphism offers a way out, allowing us to redefine (in a
derived class) members of a base class allowing these redefined members to be
used from the base class's interface.
This is the essence of LSP: public inheritance should not be used to reuse the base class members (in derived classes) but to be reused (by the base class, polymorphically using derived class members reimplementing base class members).
Take a second to appreciate the implications of the above little program. The
hello and process members aren't too impressive, but the implications
of the example are. The process member could implement directory travel,
hello could define the action to perform when encountering a
file. Base::hello might simply show the name of a file, but
Derived::hello might delete the file; might only list its name if its
younger than a certain age; might list its name if it contains a certain text;
etc., etc.. Up to now Derived would have to implement process's
actions itself; Up to now code expecting a Base class reference or pointer
could only perform Base's actions. Polymorphism allows us to reimplement
members of base classes and to use those reimplemented members in code
expecting base class references or pointers. Using polymorphism existing code
may be reused by derived classes reimplementing the appropriate members of
their base classes. It's about time to uncover how this magic can be realized.
Polymorphism, which is not the default in C++, solves the problem and
allows the author of the classes to reach its goal. For the curious reader:
prefix void hello() in the Base class with the keyword virtual and
recompile. Running the modified program produces the intended and expected
derived hello. Why this happens is explained next.
Vehicle * activates Vehicle's member
functions, even when pointing to an object of a derived class. This is known
as as early or
static binding: the function to
call is determined at
compile-time. In C++ late
or dynamic binding is realized using
virtual member functions.
A member function becomes a virtual member function when its declaration
starts with the keyword virtual. It is stressed once again that in
C++, different from several other object oriented languages, this is
not the default situation. By default static binding is used.
Once a function is declared virtual in a base class, it remains virtual in
all derived classes. The keyword virtual should not be mentioned for
members in derived classes which are declared virtual in base classes. In
derived classes those members should be provided with the override
indicator, allowing the compiler to verify that you're indeed referring to an
existing virtual member function.
In the vehicle classification system (see section 13.1), let's
concentrate on the members mass and setMass. These members define the
user interface of the class Vehicle. What we would like to accomplish
is that this user interface can be used for Vehicle and for any class
inheriting from Vehicle, since objects of those classes are themselves
also Vehicles.
If we can define the user interface of our base class (e.g., Vehicle) such
that it remains usable irrespective of the classes we derive from Vehicle
our software achieves an enormous reusability: we design our software around
Vehicle's user interface, and our software will also properly function for
derived classes. Using plain inheritance doesn't accomplish this. If we define
std::ostream &operator<<(std::ostream &out, Vehicle const &vehicle)
{
return out << "Vehicle's mass is " << vehicle.mass() << " kg.";
}
and Vehicle's member mass returns 0, but Car's member
mass returns 1000, then twice a mass of 0 is reported when the following
program is executed:
int main()
{
Vehicle vehicle;
Car vw{ 1000, 160, "Golf" };
cout << vehicle << '\n' << vw << '\n';
}
We've defined an overloaded insertion operator, but since it only knows
about Vehicle's user interface, `cout << vw' will use vw's
Vehicle's user interface as well, thus displaying a mass of 0.
Reusability is enhanced if we add a redefinable interface to the base class's interface. A redefinable interface allows derived classes to fill in their own implementation, without affecting the user interface. At the same time the user interface will behave according to the derived class's wishes, and not just to the base class's default implementation.
Members of the reusable interface should be declared in the class's
private sections: conceptually they merely belong to their own classes
(cf. section 14.7). In the base class these members should be
declared virtual. These members can be redefined (overridden) by derived
classes, and should there be provided with override indicators.
We keep our user interface (mass), and add the redefinable member
vmass to Vehicle's interface:
class Vehicle
{
public:
size_t mass() const;
size_t si_mass() const; // see below
private:
virtual size_t vmass() const;
};
Separating the user interface from the redefinable interface is a sensible thing to do. It allows us to fine-tune the user interface (only one point of maintenance), while at the same time allowing us to standardize the expected behavior of the members of the redefinable interface. E.g., in many countries the International system of units is used, using the kilogram as the unit for mass. Some countries use other units (like the lbs: 1 kg being approx. 2.2046 lbs). By separating the user interface from the redefinable interface we can use one standard for the redefinable interface, and keep the flexibility of transforming the information ad-lib in the user interface.
Just to maintain a clean separation of user- and redefinable interface we
might consider adding another accessor to Vehicle, providing the
si_mass, simply implemented like this:
size_t Vehicle::si_mass() const
{
return vmass();
}
If Vehicle supports a member d_massFactor then its mass member can
be implemented like this:
size_t Vehicle::mass()
{
return d_massFactor * si_mass();
}
Vehicle itself could define vmass so that it returns a token
value. E.g.,
size_t Vehicle::vmass()
{
return 0;
}
Now let's have a look at the class Car. It is derived from
Vehicle, and it inherits Vehicle's user interface. It also has a data
member size_t d_mass, and it implements its own reusable interface:
class Car: public Vehicle
{
...
private:
size_t vmass() override;
}
If Car constructors require us to specify the car's mass (stored
in d_mass), then Car simply implements its vmass member like
this:
size_t Car::vmass() const
{
return d_mass;
}
The class Truck, inheriting from Car needs two mass values: the
tractor's mass and the trailer's mass. The tractor's mass is passed to its
Car base class, the trailor's mass is passed to its Vehicle d_trailor
data member. Truck, too, overrides vmass, this time returning the sum
of its tractor and trailor masses:
size_t Truck::vmass() const
{
return Car::si_mass() + d_trailer.si_mass();
}
Once a class member has been declared virtual it becomes
a virtual member in all derived classes, whether or not these members are
provided with the override indicator. But override should be used,
as it allows to compiler to catch typos when writing down the derived class
interface.
A member function may be declared virtual anywhere in a
class hierarchy, but this probably defeats the underlying polymorphic
class design, as the original base class is no longer capable of completely
covering the redefinable interfaces of derived classes. If, e.g, mass is
declared virtual in Car, but not in Vehicle, then the specific
characteristics of virtual member functions would only be available for
Car objects and for objects of classes derived from Car. For a
Vehicle pointer or reference static binding would remain to be used.
The effect of late binding (polymorphism) is illustrated below:
void showInfo(Vehicle &vehicle)
{
cout << "Info: " << vehicle << '\n';
}
int main()
{
Car car(1200); // car with mass 1200
Truck truck(6000, 115, // truck with cabin mass 6000,
"Scania", 15000); // speed 115, make Scania,
// trailer mass 15000
showInfo(car); // see (1) below
showInfo(truck); // see (2) below
Vehicle *vp = &truck;
cout << vp->speed() << '\n';// see (3) below
}
Now that mass is defined virtual, late binding is used:
Car's mass is displayed;
Truck's mass is displayed;
speed is not a member of Vehicle, and hence not callable via
a Vehicle*.
virtual characteristic
only influences the type of binding (early vs. late), not the set of member
functions that is visible to the pointer.
Through virtual members derived classes may redefine the behavior performed by functions called from base class members or from pointers or references to base class objects. This redefinition of base class members by derived classes is called overriding members.
Vehicle would
define these members:
public:
void Vehicle::prepare()
{
vPrepare();
}
private:
virtual void Vehicle::vPrepare()
{
cout << "Preparing the Vehicle\n";
}
and Car would override vPrepare:
virtual void Car::vPrepare()
{
cout << "Preparing the Car\n";
}
then Preparing the Car would be shown by the following code fragment:
Car car{1200};
Vehicle &veh = car;
veh.prepare();
Maybe a preparation is always required. So why not do it in the base
class's constructor? Thus, the Vehicle's constructor could be defined as:
Vehicle::Vehicle()
{
prepare();
}
However, the following code fragment shows Preparing the Vehicle,
and not Preparing the Car:
Car car{1200};
As base classes' constructors do not recognize overridden virtual members
Vehicle's constructor simply calls its own vPrepare member instead of
Vehicle::vPrepare.
There is clear logic to base class constructors not recognizing overridden member functions: polymorphism allows us to tailor the base class's interface to derived classes. Virtual members exist to realize this tailoring process. But that's completely different from not being able to call derived classes' members from base classes' constructors: at that point the derived class objects haven't yet properly been initialized. When derived class objects are constructed their base class parts are constructed before the derived class objects themselves are in a valid state. Therefore, if a base class constructor would be allowed to call an overridden virtual member then that member would most likely use data of the derived class, which at that point haven't properly been initialized yet (often resulting in undefined behavior like segmentation faults).
Vehicle *vp = new Land{ 1000, 120 };
delete vp; // object destroyed
Here delete is applied to a base class pointer. As the base class
defines the available interface delete vp calls ~Vehicle and ~Land
remains out of sight. Assuming that Land allocates memory a
memory leak results. Freeing memory is not the only action destructors can
perform. In general they may perform any action that's necessary when an
object ceases to exist. But here none of the actions defined by ~Land are
performed. Bad news....
In C++ this problem is solved by
virtual destructors. A
destructor can be declared virtual. When a base class destructor is
declared virtual then the destructor of the actual class pointed to by a base
class pointer bp is going to be called when delete bp is
executed. Thus, late binding is realized for destructors even though the
destructors of derived classes have unique names. Example:
class Vehicle
{
public:
virtual ~Vehicle(); // all derived class destructors are
// now virtual as well.
};
By declaring a virtual destructor, the above delete operation
(delete vp) correctly calls Land's destructor, rather than
Vehicle's destructor.
Once a destructor is called it performs as usual, whether or not it
is a virtual destructor. So, ~Land first executes its own statements
and then calls ~Vehicle. Thus, the above delete vp statement
uses late binding to call ~Vehicle and from this point on the object
destruction proceeds as usual.
Destructors should always be defined virtual in classes designed as a
base class from which other classes are going to be derived. Often those
destructors themselves have no tasks to perform. In these cases the virtual
destructor is given an empty body. For example, the definition of
Vehicle::~Vehicle() may be as simple as:
Vehicle::~Vehicle()
{}
Resist the temptation to define virtual destructors (even empty destructors) inline as this complicates class maintenance. Section 14.11 discusses the reason behind this rule of thumb.
Vehicle is provided with its own concrete implementations
of its virtual members (mass and setMass). However, virtual member
functions do not necessarily have to be implemented in base classes.
When the implementations of virtual members are omitted from base classes the class imposes requirements upon derived classes. The derived classes are required to provide the `missing implementations'.
This approach, in some languages (like C#, Delphi and Java) known as an interface, defines a protocol. Derived classes must obey the protocol by implementing the as yet not implemented members. If a class contains at least one member whose implementation is missing no objects of that class can be defined.
Such incompletely defined classes are always base classes. They enforce a protocol by merely declaring names, return values and arguments of some of their members. These classes are call abstract classes or abstract base classes. Derived classes become non-abstract classes by implementing the as yet not implemented members.
Abstract base classes are the foundation of many design patterns (cf. Gamma et al. (1995)) , allowing the programmer to create highly reusable software. Some of these design patterns are covered by the C++ Annotations (e.g, the Template Method in section 26.2), but for a thorough discussion of design patterns the reader is referred to Gamma et al.'s book.
Members that are merely declared in base classes are called
pure virtual functions. A virtual member becomes a pure virtual member
by postfixing = 0 to its declaration (i.e., by replacing the semicolon
ending its declaration by `= 0;'). Example:
#include <iosfwd>
class Base
{
public:
virtual ~Base();
virtual std::ostream &insertInto(std::ostream &out) const = 0;
};
inline std::ostream &operator<<(std::ostream &out, Base const &base)
{
return base.insertInto(out);
}
All classes derived from Base must implement the insertInto
member function, or their objects cannot be constructed. This is neat: all
objects of class types derived from Base can now always be inserted into
ostream objects.
Could the virtual destructor of a base class ever be a pure virtual
function? The answer to this question is no. First of all, there is no need to
enforce the availability of destructors in derived classes as destructors are
provided by default (unless a destructor is declared with the = delete
attribute). Second, if it is a pure virtual member its implementation does not
exist. However, derived class destructors eventually call their base class
destructors. How could they call base class destructors if their
implementations are lacking? More about this in the next section.
Often, but not necessarily, pure virtual member functions are
const member functions. This allows the
construction of constant derived class objects. In other situations this might
not be necessary (or realistic), and
non-constant member functions might be required. The general rule for
const member functions also applies to pure virtual functions: if the
member function alters the object's data members, it cannot be a const
member function.
Abstract base classes frequently don't have
data members. However, once a base class
declares a pure virtual member it must be declared identically in derived
classes. If the implementation of a pure virtual function in a derived class
alters the derived class object's data, then that function cannot be
declared as a const member. Therefore, the author of an abstract base
class should carefully consider whether a pure virtual member function should
be a const member function or not.
= 0; specification, but
implement it as well. Since the = 0; ends in a semicolon, the pure virtual
member is always at most a declaration in its class, but an implementation may
either be provided outside from its interface (maybe using inline).
Pure virtual member functions may be called from derived class objects or from its class or derived class members by specifying the base class and scope resolution operator together with the member to be called. Example:
#include <iostream>
class Base
{
public:
virtual ~Base();
virtual void pureimp() = 0;
};
Base::~Base()
{}
void Base::pureimp()
{
std::cout << "Base::pureimp() called\n";
}
class Derived: public Base
{
public:
void pureimp() override;
};
inline void Derived::pureimp()
{
Base::pureimp();
std::cout << "Derived::pureimp() called\n";
}
int main()
{
Derived derived;
derived.pureimp();
derived.Base::pureimp();
Derived *dp = &derived;
dp->pureimp();
dp->Base::pureimp();
}
// Output:
// Base::pureimp() called
// Derived::pureimp() called
// Base::pureimp() called
// Base::pureimp() called
// Derived::pureimp() called
// Base::pureimp() called
Implementing a pure virtual member has limited use. One could argue that the pure virtual member function's implementation may be used to perform tasks that can already be performed at the base class level. However, there is no guarantee that the base class virtual member function is actually going to be called. Therefore base class specific tasks could as well be offered by a separate member, without blurring the distinction between a member doing some work and a pure virtual member enforcing a protocol.
Value is a value class. It offers a copy constructor,
an overloaded assignment operator, maybe move operations, and a public,
non-virtual constructor. In section 14.7 it is argued that such
classes are not suited as base classes. New classes should not inherit from
Value. How to enforce this?
Base defines a virtual member
v_process(int32_t). A class derived from Base needs to override this
member, but the author mistakingly defined v_proces(int32_t). How to
prevent such errors, breaking the polymorphic behavior of the derived class?
Derived, derived from a polymorphic Base class
overrides the member Base::v_process, but classes that are in turn derived
from Derived should no longer override v_process, but may override
other virtual members like v_call and v_display. How to enforce this
restricted polymorphic character for classes derived from Derived?
final and override are used to realize
the above. These identifiers are special in the sense that they only require
their special meanings in specific contexts. Outside of this context they are
just plain identifiers, allowing the programmer to define a variable like
bool final.
The identifier final can be applied to class declarations to indicate
that the class cannot be used as a base class. E.g.:
class Base1 final // cannot be a base class
{};
class Derived1: public Base1 // ERR: Base1 is final
{};
class Base2 // OK as base class
{};
class Derived2 final: public Base2 // OK, but Derived2 can't be
{}; // used as a base class
class Derived: public Derived2 // ERR: Derived2 is final
{};
The identifier final can also be added to virtual member
declarations. This indicates that those virtual members cannot be overridden
by derived classes. The restricted polymorphic character of a class, mentioned
above, can thus be realized as follows:
class Base
{
virtual int v_process(); // define polymorphic behavior
virtual int v_call();
virtual int v_display();
};
class Derived: public Base // Derived restricts polymorphism
{ // to v_call and v_display
virtual int v_process() final;
};
class Derived2: public Derived
{
// int v_process(); No go: Derived:v_process is final
virtual int v_display(); // OK to override
};
To allow the compiler to detect typos, differences in parameter types, or
differences in member function modifiers (e.g., const vs. non-const)
the identifier override can (should) be appended to derived class members
overriding base class members. E.g.,
class Base
{
virtual int v_process();
virtual int v_call() const;
virtual int v_display(std::ostream &out);
};
class Derived: public Base
{
virtual int v_proces() override; // ERR: v_proces != v_process
virtual int v_call() override; // ERR: not const
// ERR: parameter types differ
virtual int v_display(std::istream &out) override;
};
fstream, one class
offering features of ifstream and ofstream. In chapter
13 we learned that a class may be derived from multiple base
classes. Such a derived class inherits the properties of all its base
classes. Polymorphism can also be used in combination with multiple
inheritance.
Consider what would happen if more than one `path' leads from the derived
class up to its (base) classes. This is illustrated in the next (fictitious)
example where a class Derived is doubly derived from Base:
class Base
{
int d_field;
public:
void setfield(int val);
int field() const;
};
inline void Base::setfield(int val)
{
d_field = val;
}
inline int Base::field() const
{
return d_field;
}
class Derived: public Base, public Base
{};
Due to the double derivation, Base's functionality now occurs twice in
Derived. This results in ambiguity: when the function setfield() is
called for a Derived class object, which function will that be as there
are two of them? The scope resolution operator won't come to the rescue and so
the C++ compiler cannot compile the above example and (correctly)
identifies an error.
The above code clearly duplicates its base class in the derivation, which can
of course easily be avoided by not doubly deriving from Base (or by using
composition (!)). But duplication of a base class can also occur through
nested inheritance, where an object is derived from, e.g., a Car and
from an Air (cf. section 13.1). Such a class would be needed
to represent, e.g., a flying car (such as the one in James Bond
vs. the Man with the Golden Gun...). An AirCar would ultimately contain
two Vehicles, and hence two mass fields, two setMass()
functions and two mass() functions. Is this what we want?
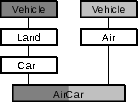
AirCar introduces ambiguity, when
derived from Car and Air.
AirCar is a Car, hence a Land, and hence a
Vehicle.
AirCar is also an Air, and hence a Vehicle.
Vehicle data is further illustrated in
Figure 16.
AirCar is shown in
Figure 17
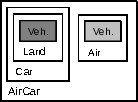
AirCar object.
AirCar object,
and will therefore not compile statements like:
AirCar jBond;
cout << jBond.mass() << '\n';
Which member function mass to call cannot be determined by the
compiler but the programmer has two possibilities to resolve the ambiguity for
the compiler:
// let's hope that the mass is kept in the Car // part of the object.. cout << jBond.Car::mass() << '\n';
The scope resolution operator and the class name are put right before the name of the member function.
mass could be created for
the class AirCar:
int AirCar::mass() const
{
return Car::mass();
}
AirCar to take special precautions.
However, there exists a more elegant solution, discussed in the next section.
AirCar represents
two Vehicles. This not only results in an ambiguity about which
function to use to access the mass data, but it also defines two
mass fields in an AirCar. This is slightly redundant, since we can
assume that an AirCar has but one mass.
It is, however, possible to define an AirCar as a class consisting of
but one Vehicle and yet using multiple derivation. This is realized by
defining the base classes that are multiply mentioned in a derived class's
inheritance tree as a
virtual base class.
For the class AirCar this implies a small change when deriving an
AirCar from Land and Air classes:
class Land: virtual public Vehicle
{
// etc
};
class Car: public Land
{
// etc
};
class Air: virtual public Vehicle
{
// etc
};
class AirCar: public Car, public Air
{
};
Virtual derivation ensures that a Vehicle is
only added once to a derived class. This means that the route along which a
Vehicle is added to an AirCar is no longer depending on its direct
base classes; we can only state that an AirCar is a Vehicle. The
internal organization of an AirCar after virtual derivation is shown in
Figure 18.

AirCar object when the base
classes are virtual.
When a class Third inherits from a base class Second which in turn
inherits from a base class First then the First class constructor
called by the Second class constructor is also used when this Second
constructor is used when constructing a Third object. Example:
class First
{
public:
First(int x);
};
class Second: public First
{
public:
Second(int x)
:
First(x)
{}
};
class Third: public Second
{
public:
Third(int x)
:
Second(x) // calls First(x)
{}
};
The above no longer holds true when Second uses virtual derivation.
When Second uses virtual derivation its base class constructor is
ignored when Second's constructor is called from Third. Instead
Second by default calls First's default constructor. This is
illustrated by the next example:
class First
{
public:
First()
{
cout << "First()\n";
}
First(int x);
};
class Second: public virtual First // note: virtual
{
public:
Second(int x)
:
First(x)
{}
};
class Third: public Second
{
public:
Third(int x)
:
Second(x)
{}
};
int main()
{
Third third{ 3 }; // displays `First()'
}
When constructing Third First's default constructor is used by
default. Third's constructor, however, may overrule this default behavior
by explicitly specifying the constructor to use. Since the First object
must be available before Second can be constructed it must be specified
first. To call First(int) when constructing Third(int) the latter
constructor can be defined as follows:
class Third: public Second
{
public:
Third(int x)
:
First(x), // now First(int) is called.
Second(x)
{}
};
This behavior may seem puzzling when simple linear inheritance is used but
it makes sense when multiple inheritance is used with base classes using
virtual inheritance. Consider AirCar: when Air and Car both
virtually inherit from Vehicle will Air and Car both initialize
the common Vehicle object? If so, which one is going to be called first?
What if Air and Car use different Vehicle constructors? All these
questions can be avoided by passing the responsibility for the initialization
of a common base class to the class eventually using the common base class
object. In the above example Third. Hence Third is provided an
opportunity to specify the constructor to use when initializing First.
Multiple inheritance may also be used to inherit from classes that do not all
use virtual inheritance. Assume we have two classes, Derived1 and
Derived2, both (possibly virtually) derived from Base.
We now address the question which constructors will be called when calling a
constructor of the class Final: public Derived1, public Derived2.
To distinguish the involved constructors Base1 indicates the Base
class constructor called as base class initializer for Derived1 (and
analogously: Base2 called from Derived2). A plain Base indicates
Base's default constructor.
Derived1 and Derived2 indicate the base class initializers used when
constructing a Final object.
Now we're ready to distinguish the various cases when constructing an object
of the class Final: public Derived1, public Derived2:
Derived1: public Base Derived2: public Base
This is normal, non virtual multiple derivation. The following constructors are called in the order shown:Base1, Derived1, Base2, Derived2
Derived1: public Base Derived2: virtual public Base
OnlyDerived2uses virtual derivation.Derived2's base class constructor is ignored. Instead,Baseis called and it is called prior to any other constructor:Base, Base1, Derived1, Derived2As only one class uses virtual derivation, two
Baseclass objects remain available in the eventualFinalclass.
Derived1: virtual public Base Derived2: public Base
OnlyDerived1uses virtual derivation.Derived1's base class constructor is ignored. Instead,Baseis called and it is called prior to any other constructor. Different from the first (non-virtual) caseBaseis now called, rather thanBase1:Base, Derived1, Base2, Derived2
Derived1: virtual public Base Derived2: virtual public Base
Both base classes use virtual derivation and so only oneBaseclass object will be present in theFinalclass object. The following constructors are called in the order shown:Base, Derived1, Derived2
Truck (cf.
section 13.5):
class Truck: public Car
{
int d_trailer_mass;
public:
Truck();
Truck(int engine_mass, int sp, char const *nm,
int trailer_mass);
void setMass(int engine_mass, int trailer_mass);
int mass() const;
};
Truck::Truck(int engine_mass, int sp, char const *nm,
int trailer_mass)
:
Car(engine_mass, sp, nm)
{
d_trailer_mass = trailer_mass;
}
int Truck::mass() const
{
return // sum of:
Car::mass() + // engine part plus
trailer_mass; // the trailer
}
This definition shows how a Truck object is constructed to contain two
mass fields: one via its derivation from Car and one via its own int
d_trailer_mass data member. Such a definition is of course valid, but it
could also be rewritten. We could derive a Truck from a Car
and from a Vehicle, thereby explicitly requesting the double presence
of a Vehicle; one for the mass of the engine and cabin, and one for the
mass of the trailer. A slight complication is that a class organization like
class Truck: public Car, public Vehicle
is not accepted by the C++ compiler. As a Vehicle is already part
of a Car, it is therefore not needed once again. This organization may,
however, be accepted using a small trick. By creating an additional class
inheriting from Vehicle and deriving Truck from that additional class
rather than directly from Vehicle the problem is solved. Simply derive a
class TrailerVeh from Vehicle, and then Truck from Car and
TrailerVeh:
class TrailerVeh: public Vehicle
{
public:
TrailerVeh(int mass)
:
Vehicle(mass)
{}
};
class Truck: public Car, public TrailerVeh
{
public:
Truck();
Truck(int engine_mass, int sp, char const *nm, int trailer_mass);
void setMass(int engine_mass, int trailer_mass);
int mass() const;
};
inline Truck::Truck(int engine_mass, int sp, char const *nm,
int trailer_mass)
:
Car(engine_mass, sp, nm),
TrailerVeh(trailer_mass)
{}
inline int Truck::mass() const
{
return // sum of:
Car::mass() + // engine part plus
TrailerVeh::mass(); // the trailer
}
typeid operators.
dynamic_cast is used to convert a base
class pointer or reference to a
derived class pointer or reference. This is also known as down-casting.
typeid operator returns the actual type of an expression.
dynamic_cast<> operator is used to convert a base
class pointer or reference to,
respectively, a derived class pointer or reference. This is also called
down-casting as direction of the cast is down the inheritance tree.
A dynamic cast's actions are determined run-time; it can only be used if
the base class declares at least one virtual member function. For the dynamic
cast to succeed, the destination class's Vtable must be equal to the
Vtable to which the dynamic cast's argument refers to, lest the cast fails
and returns 0 (if a dynamic cast of a pointer was requested) or throws a
std::bad_cast exception (if a dynamic cast of a reference was requested).
In the following example a pointer to the class Derived is obtained from
the Base class pointer bp:
class Base
{
public:
virtual ~Base();
};
class Derived: public Base
{
public:
char const *toString();
};
inline char const *Derived::toString()
{
return "Derived object";
}
int main()
{
Base *bp;
Derived *dp,
Derived d;
bp = &d;
dp = dynamic_cast<Derived *>(bp);
if (dp)
cout << dp->toString() << '\n';
else
cout << "dynamic cast conversion failed\n";
}
In the condition of the above if statement the success of the dynamic
cast is verified. This verification is performed at run-time, as the
actual class of the objects to which the pointer points is only known by then.
If a base class pointer is provided, the dynamic cast operator returns 0 on failure and a pointer to the requested derived class on success.
Assume a vector<Base *> is used. The pointers of such a vector may
point to objects of various classes, all derived from Base. A dynamic cast
returns a pointer to the specified class if the base class pointer indeed
points to an object of the specified class and returns 0 otherwise.
We could determine the actual class of an object a pointer points to by performing a series of checks to find the derived class to which a base class pointer points. Example:
class Base
{
public:
virtual ~Base();
};
class Derived1: public Base;
class Derived2: public Base;
int main()
{
vector<Base *> vb(initializeBase());
Base *bp = vb.front();
if (dynamic_cast<Derived1 *>(bp))
cout << "bp points to a Derived1 class object\n";
else if (dynamic_cast<Derived2 *>(bp))
cout << "bp points to a Derived2 class object\n";
}
Alternatively, a reference to a base class object may be available. In
this case the dynamic_cast operator throws an exception if the down
casting fails. Example:
#include <iostream>
#include <typeinfo>
class Base
{
public:
virtual ~Base();
virtual char const *toString();
};
inline char const *Base::toString()
{
return "Base::toString() called";
}
class Derived1: public Base
{};
class Derived2: public Base
{};
Base::~Base()
{}
void process(Base &b)
{
try
{
std::cout << dynamic_cast<Derived1 &>(b).toString() << '\n';
}
catch (std::bad_cast)
{}
try
{
std::cout << dynamic_cast<Derived2 &>(b).toString() << '\n';
}
catch (std::bad_cast)
{
std::cout << "Bad cast to Derived2\n";
}
}
int main()
{
Derived1 d;
process(d);
}
/*
Generated output:
Base::toString() called
Bad cast to Derived2
*/
In this example the value std::bad_cast is used. A
std::bad_cast exception is thrown if the dynamic cast of a reference to a
derived class object fails.
Note the form of the catch clause: bad_cast is the name of a type.
Section 17.4.1 describes how such a type can be defined.
The dynamic cast operator is a useful tool when an existing base class cannot or should not be modified (e.g., when the sources are not available), and a derived class may be modified instead. Code receiving a base class pointer or reference may then perform a dynamic cast to the derived class to access the derived class's functionality.
You may wonder in what way the behavior of the dynamic_cast differs from
that of the static_cast.
When the static_cast is used, we tell the compiler that it must convert a
pointer or reference to its expression type to a pointer or reference of its
destination type. This holds true whether the base class declares virtual
members or not. Consequently, all the static_cast's actions can be
determined by the compiler, and the following compiles fine:
class Base
{
// maybe or not virtual members
};
class Derived1: public Base
{};
class Derived2: public Base
{};
int main()
{
Derived1 derived1;
Base *bp = &derived1;
Derived1 &d1ref = static_cast<Derived1 &>(*bp);
Derived2 &d2ref = static_cast<Derived2 &>(*bp);
}
Pay attention to the second static_cast: here the Base class
object is cast to a Derived2 class reference. The compiler has no problems
with this, as Base and Derived2 are related by inheritance.
Semantically, however, it makes no sense as bp in fact points to a
Derived1 class object. This is detected by a dynamic_cast. A
dynamic_cast, like the static_cast, converts related pointer or
reference types, but the dynamic_cast provides a run-time safeguard. The
dynamic cast fails when the requested type doesn't match the actual type of
the object we're pointing at. In addition, the dynamic_cast's use is much
more restricted than the static_cast's use, as the dynamic_cast can
only be used for downcasting to derived classes having virtual members.
In the end a dynamic cast is a cast, and casts should be avoided whenever possible. When the need for dynamic casting arises ask yourself whether the base class has correctly been designed. In situations where code expects a base class reference or pointer the base class interface should be all that is required and using a dynamic cast should not be necessary. Maybe the base class's virtual interface can be modified so as to prevent the use of dynamic casts. Start frowning when encountering code using dynamic casts. When using dynamic casts in your own code always properly document why the dynamic cast was appropriately used and was not avoided.
dynamic_cast operator, typeid is usually applied to
references to base class objects that refer to derived class
objects. Typeid should only be used with base classes offering virtual
members.
Before using typeid the <typeinfo> header file must be included.
The typeid operator returns an object of type type_info.
Different compilers may offer different implementations of the class
type_info, but at the very least typeid must offer the following
interface:
class type_info
{
public:
virtual ~type_info();
int operator==(type_info const &other) const;
int operator!=(type_info const &other) const;
bool before(type_info const &rhs) const;
char const *name() const;
private:
type_info(type_info const &other);
type_info &operator=(type_info const &other);
};
Note that this class has a private copy constructor and a private
overloaded assignment operator. This prevents code from constructing
type_info objects and prevents code from assigning type_info objects
to each other. Instead, type_info objects are
constructed and returned by the typeid operator.
If the typeid operator is passed a base class reference it is able to
return the actual name of the type the reference refers to. Example:
class Base;
class Derived: public Base;
Derived d;
Base &br = d;
cout << typeid(br).name() << '\n';
In this example the typeid operator is given a base class reference.
It prints the text ``Derived'', being the class name of the class
br actually refers to. If Base does not contain virtual functions, the
text ``Base'' is printed.
The typeid operator can be used to determine the name of the actual
type of expressions, not just of class type
objects. For example:
cout << typeid(12).name() << '\n'; // prints: int
cout << typeid(12.23).name() << '\n'; // prints: double
Note, however, that the above example is suggestive at most. It may
print int and double, but this is not necessarily the case. If
portability is required, make sure no tests against these static, built-in
text-strings are required. Check out what your compiler produces in case of
doubt.
In situations where the typeid operator is applied to
determine the type of a derived class, a base class reference
should be used as the argument of the typeid operator. Consider
the following example:
class Base; // contains at least one virtual function
class Derived: public Base;
Base *bp = new Derived; // base class pointer to derived object
if (typeid(bp) == typeid(Derived *)) // 1: false
...
if (typeid(bp) == typeid(Base *)) // 2: true
...
if (typeid(bp) == typeid(Derived)) // 3: false
...
if (typeid(bp) == typeid(Base)) // 4: false
...
if (typeid(*bp) == typeid(Derived)) // 5: true
...
if (typeid(*bp) == typeid(Base)) // 6: false
...
Base &br = *bp;
if (typeid(br) == typeid(Derived)) // 7: true
...
if (typeid(br) == typeid(Base)) // 8: false
...
Here, (1) returns false as a Base * is not a Derived
*. (2) returns true, as the two pointer types are the same, (3)
and (4) return false as pointers to objects are not the objects
themselves.
On the other hand, if *bp is used in the above expressions, then
(1) and (2) return false as an object (or reference to an object)
is not a pointer to an object, whereas (5) now returns true: *bp
actually refers to a Derived class object, and typeid(*bp) returns
typeid(Derived). A similar result is obtained if a base class reference
is used: 7 returning true and 8 returning false.
The type_info::before(type_info const &rhs) member is used to
determine the collating order of classes. This is useful when comparing
two types for equality. The function returns a nonzero value if *this
precedes rhs in the hierarchy or collating order of the used types. When a
derived class is compared to its base class the comparison returns 0,
otherwise a non-zero value. E.g.:
cout << typeid(ifstream).before(typeid(istream)) << '\n' << // 0
typeid(istream).before(typeid(ifstream)) << '\n'; // not 0
With built-in types the implementor may implement that non-0 is returned when a `wider' type is compared to a `smaller' type and 0 otherwise:
cout << typeid(double).before(typeid(int)) << '\n' << // not 0
typeid(int).before(typeid(double)) << '\n'; // 0
When two equal types are compared, 0 is returned:
cout << typeid(ifstream).before(typeid(ifstream)) << '\n'; // 0
When a 0-pointer is passed to the operator typeid a bad_typeid
exception is thrown.
We've seen that polymorphic classes on the one hand offer interface members defining the functionality that can be requested of base classes and on the other hand offer virtual members that can be overridden. One of the signs of good class design is that member functions are designed according to the principle of `one function, one task'. In the current context: a class member should either be a member of the class's public or protected interface or it should be available as a virtual member for reimplementation by derived classes. Often this boils down to virtual members that are defined in the base class's private section. Those functions shouldn't be called by code using the base class, but they exist to be overridden by derived classes using polymorphism to redefine the base class's behavior.
The underlying principle was mentioned before in the introductory paragraph of this chapter: according to the Liskov Substitution Principle (LSP) an is-a relationship between classes (indicating that a derived class object is a base class object) implies that a derived class object may be used in code expecting a base class object.
In this case inheritance is used not to let the derived class use the facilities already implemented by the base class but to reuse the base class polymorphically by reimplementing the base class's virtual members in the derived class.
In this section we'll discuss the reasons for using inheritance. Why should inheritance (not) be used? If it is used what do we try to accomplish by it?
Inheritance often competes with composition. Consider the following two alternative class designs:
class Derived: public Base
{ ... };
class Composed
{
Base d_base;
...
};
Why and when prefer Derived over Composed and vice versa? What
kind of inheritance should be used when designing the class Derived?
Composed and Derived are offered as alternatives we are
looking at the design of a class (Derived or Composed) that
is-implemented-in-terms-of another class.
Composed does itself not make Base's interface
available, Derived shouldn't do so either. The underlying
principle is that private inheritance should be used when
deriving a classs Derived from Base where Derived
is-implemented-in-terms-of Base.
std::string members) which can not be realized using
inheritance.
Base offers members in its protected interface that
must be used when implementing Derived inheritance must also
be used. Again: since we're implementing-in-terms-of the
inheritance type should be private.
D) itself is intended as a base class that should only make
the members of its own base class (B) available to classes
that are derived from it (i.e., D).
Private inheritance should also be used when a derived class is-a certain
type of base class, but in order to initialize that base class an object of
another class type must be available. Example: a new istream class-type
(say: a stream IRandStream from which random numbers can be extracted) is
derived from std::istream. Although an istream can be constructed
empty (receiving its streambuf later using its rdbuf member), it is
clearly preferable to initialize the istream base class right away.
Assuming that a Randbuffer: public std::streambuf has been created for
generating random numbers then IRandStream can be derived from
Randbuffer and std::istream. That way the istream base class can
be initialized using the Randbuffer base class.
As a RandStream is definitely not a Randbuffer public inheritance
is not appropriate. In this case IRandStream
is-implemented-in-terms-of a Randbuffer and so private inheritance
should be used.
IRandStream's class interface should therefore start like this:
class IRandStream: private Randbuffer, public std::istream
{
public:
IRandStream(int lowest, int highest) // defines the range
:
Randbuffer(lowest, highest),
std::istream(this) // passes &Randbuffer
{}
...
};
Public inheritance should be reserved for classes for which the LSP holds true. In those cases the derived classes can always be used instead of the base class from which they derive by code merely using base class references, pointers or members (I.e., conceptually the derived class is-a base class). This most often applies to classes derived from base classes offering virtual members. To separate the user interface from the redefinable interface the base class's public interface should not contain virtual members (except for the virtual destructor) and the virtual members should all be in the base class's private section. Such virtual members can still be overridden by derived classes (this should not come as a surprise, considering how polymorphism is implemented) and this design offers the base class full control over the context in which the redefined members are used. Often the public interface merely calls a virtual member, but those members can always be redefined to perform additional duties.
The prototypical form of a base class therefore looks like this:
class Base
{
public:
virtual ~Base();
void process(); // calls virtual members (e.g.,
// v_process)
private:
virtual void v_process(); // overridden by derived classes
};
Alternatively a base class may offer a non-virtual destructor, which should then be protected. It shouldn't be public to prevent deleting objects through their base class pointers (in which case virtual destructors should be used). It should be protected to allow derived class destructors to call their base class destructors. Such base classes should, for the same reasons, have non-public constructors and overloaded assignment operators.
std::streambuf receives the character sequences
processed by streams and defines the interface between stream objects and
devices (like a file on disk). A streambuf object is usually not directly
constructed, but usually it is used as base class of some derived class
implementing the communication with some concrete device.
The primary reason for existence of the class streambuf is to decouple
the stream classes from the devices they operate upon. The rationale here
is to add an extra layer between the classes allowing us to communicate with
devices and the devices themselves. This implements a chain of command
which is seen regularly in software design.
The chain of command is considered a generic pattern when designing reusable software, encountered also in, e.g., the TCP/IP stack.
A streambuf provides yet another example of the chain of command
pattern: the program talks to stream objects, which in turn forward
requests to streambuf objects, which in turn communicate with the
devices. Thus, as we will see shortly, we are able to do in user-software what
had to be done via (expensive) system calls before.
The class streambuf has no public constructor, but does make available
several public member functions. In addition to these public member functions,
several member functions are only available to classes derived from
streambuf. In section 14.8.3 a predefined specialization of the
class streambuf is introduced. All public members of streambuf
discussed here are also available in filebuf.
The next section shows the streambuf members that may be overridden
when deriving classes from streambuf. Chapter 26 offers
concrete examples of classes derived from streambuf.
The class streambuf is used by streams performing input operations and
by streams performing output operations and their member functions can be
ordered likewise. The type std::streamsize used below may,
for all practical purposes, be considered equal to the type size_t.
When inserting information into ostream objects the information is
eventually passed on to the ostream's streambuf. The streambuf may
decide to throw an exception. However, this exception does not leave the
ostream using the streambuf. Rather, the exception is caught by the
ostream, which sets its ios::bad_bit. Exceptions thrown by
manipulators which are inserted into ostream objects are not caught by
ostream objects.
Public members for input operations
std::streamsize in_avail():EOF position).
int sbumpc():EOF is returned. The returned
character is removed from the streambuf object. If no input is
available, sbumpc calls the (protected) member uflow (see
section 14.8.1 below) to make new characters
available. EOF is returned if no more characters are
available.
int sgetc():EOF is returned. The character
is not removed from the streambuf object (i.e., the
streambif's offset position isn't incremented). To remove a
character from the streambuf object, sbumpc (or sgetn) can
be used.
int sgetn(char *buffer, std::streamsize n):n characters are retrieved from the input buffer, and
stored in buffer. The actual number of characters read is
returned. The (protected) member xsgetn (see section
14.8.1 below) is called to obtain the requested number of
characters.
int snextc():EOF is returned. The character
is not removed from the streambuf object.
int sputbackc(char c):c into the streambuf's buffer to be returned as the
next character to read from the streambuf object. Caution should
be exercised when using this function: often there is a maximum of
just one character that can be put back.
int sungetc():Public members for output operations
int pubsync():streambuf's buffer to the
device. Normally only used by classes derived from streambuf.
int sputc(char c):c is inserted into the streambuf object. If, after
writing the character, the buffer is full, the function calls the
(protected) member function overflow to flush the buffer to the
device (see section 14.8.1 below).
int sputn(char const *buffer, std::streamsize n):n characters from buffer are inserted into the
streambuf object. The actual number of characters inserted is
returned. This member function calls the (protected) member xsputn
(see section 14.8.1 below) to insert the requested number of
characters.
Public members for miscellaneous operations
The next three members are normally only used by classes derived from
streambuf.
ios::pos_type pubseekoff(ios::off_type offset, ios::seekdir way,
ios::openmode mode = ios::in | ios::out):offset, relative to the standard ios::seekdir
values indicating the direction of the seeking operation.
ios::pos_type pubseekpos(ios::pos_type pos,
ios::openmode mode = ios::in | ios::out):pos.
streambuf *pubsetbuf(char* buffer, std::streamsize n):streambuf object is going to use buffer, which may contain
at least n characters.
streambuf are important for
understanding and using streambuf objects. Although there are both
protected data members and protected member functions
defined in the class streambuf using the protected
data members is strongly discouraged as using them violates the principle
of data hiding. As streambuf's set of member functions is quite
extensive, it is hardly ever necessary to use its data members directly. The
following subsections do not even list all protected member functions but only
those are covered that are useful for constructing specializations.
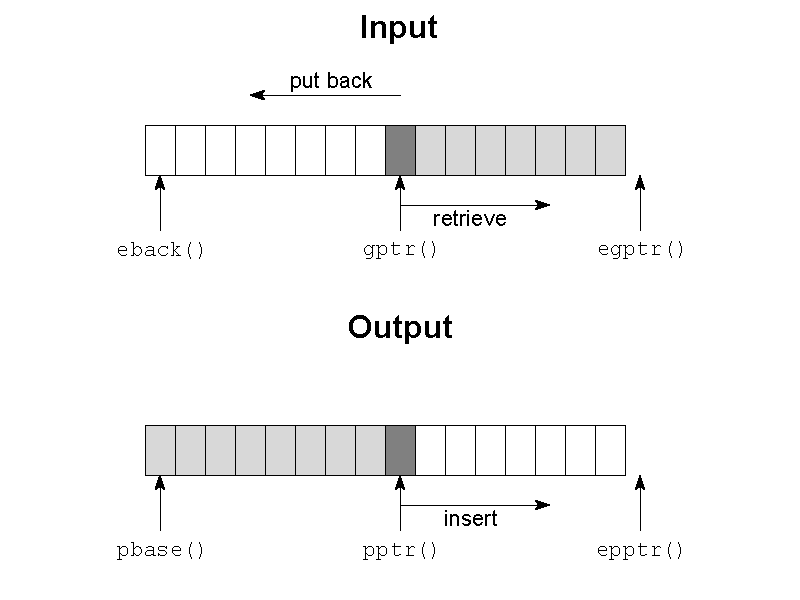
Streambuf objects control a buffer, used for input and/or output, for
which begin-, actual- and end-pointers have been defined, as depicted in
figure 19.
Streambuf offers two protected constructors:
streambuf::streambuf():class streambuf.
streambuf::streambuf(streambuf const &rhs):class streambuf. Note that
this copy constructor merely copies the values of the data members of rhs:
after using the copy constructor both streambuf objects refer to the same
data buffer and initially their pointers point at identical positions. Also
note that these are not shared pointers, but only `raw copies'.
virtual may of course be redefined in derived
classes:
char *eback():Streambuf maintains three pointers controlling its input buffer:
eback points to the `end of the putback' area: characters can
safely be put back up to this position. See also figure
19. Eback points to the beginning of the input
buffer.
char *egptr():Egptr points just beyond the last character that can be retrieved
from the input buffer. See also figure 19. If gptr
equals egptr the buffer must be refilled which is
handled by member underflow, see below.
void gbump(int n):gptr (see below) is advanced over n positions.
char *gptr():Gptr points to the next character to be
retrieved from the object's input buffer. See also figure
19.
virtual int pbackfail(int c):c fails. One
might consider restoring the old read pointer when input buffer's
begin has been reached. This member function is called when ungetting
or putting back a character fails. In particular, it is called when
gptr() == 0: no buffering used,
gptr() == eback(): no more room to push back,
*gptr() != c: a different character than the next character
to be read must be pushed back.
c == endOfFile() then the input device must be reset by one
character position. Otherwise c must be prepended to the
characters to be read. The function should return EOF on
failure. Otherwise 0 can be returned.
void setg(char *beg, char *next, char *beyond):beg points to the beginning of the
input area, next points to the next character to be retrieved, and
beyond points to the location just beyond the input buffer's last
character. Often next is at least beg + 1, to allow a put back
operation. No input buffering is used when this member is called as
setg(0, 0, 0). See also the member uflow, below.
virtual streamsize showmanyc():uflow or
underflow returns EOF. By default 0 is returned (meaning
no or some characters are returned before the latter two functions
return EOF). When a positive value is returned then the next
call of u(nder)flow does not return EOF.
virtual int uflow():underflow
(see below) to reload the input buffer. If underflow fails,
EOF is returned. Otherwise, the next available character
(*gptr()) is returned as an unsigned char, and then increments
gptr. This is different from
underflow, which merely returns the next available character,
without incrementing gptr's position.
When the streambuf doesn't use input buffering this function,
rather than underflow, can be overridden to produce the next
available character from the device.
virtual int underflow():EOF.
It is called when
eback() == 0)
gptr() >= egptr(): the input buffer is exhausted.
Often, when buffering is used, the complete buffer is not refreshed as this would make it impossible to put back characters immediately following a reload. Instead, buffers are often refreshed in halves. This system is called a split buffer.
Classes derived from streambuf for reading normally at least
override underflow. The prototypical example of an overridden
underflow function looks like this:
int underflow()
{
if (not refillTheBuffer()) // assume a member d_buffer is available
return EOF;
// reset the input buffer pointers
setg(d_buffer, d_buffer, d_buffer + d_nCharsRead);
// return the next available character
// (the cast is used to prevent
// misinterpretations of 0xff characters
// as EOF)
return static_cast<unsigned char>(*gptr());
}
This example can be used by streams reading the information made
available by devices. Section 14.8.2 covers a more
complex situation: stream supporting both input and output.
virtual streamsize xsgetn(char *buffer, streamsize n):n characters from the input device. The default
implementation is to call sbumpc for every single character
meaning that by default this member (eventually) calls underflow
for every single character. The function returns the actual number of
characters read or EOF. Once EOF is returned the
streambuf stops reading the device (see also section
14.8.2.)
virtual int overflow(int c):c is initialized to the next character
to be processed. If no output buffering is used overflow is called
for every single character that is written to the streambuf
object. No output buffering is accomplished by setting the buffer
pointers (using, setp, see below) to 0. The
default implementation returns EOF, indicating that no
characters can be written to the device.
Classes derived from streambuf for writing normally at least
override overflow. The prototypical example of an overridden
overflow function looks like this (see also section
14.8.2):
int OFdStreambuf::overflow(int c)
{
sync(); // flush the buffer
if (c != EOF) // write a character?
{
*pptr() = static_cast<char>(c); // put it into the buffer
pbump(1); // advance the buffer's pointer
}
unsigned char ch = c;
return ch;
}
char *pbase():Streambuf maintains three pointers controlling its output buffer:
pbase points to the beginning of the output buffer area. See also
figure 19.
char *epptr():Streambuf maintains three pointers controlling its output buffer:
epptr points just beyond the output buffer's last available
location. See also figure 19. If pptr (see below)
equals epptr the buffer must be flushed. This is implemented by
calling overflow, see before.
void pbump(int n):pptr (see below) is advanced by n
positions. The next character will be written at that location.
char *pptr():Streambuf maintains three pointers controlling its output buffer:
pptr points to the location in the output buffer where the next
available character will be written (note that in order to write a
character pptr() must point to a location in the range pbase()
to epptr()). See also figure 19.
void setp(char *beg, char *beyond):Streambuf's output buffer is initialized to the locations passed
to setp. Beg points to the beginning of the output buffer and
beyond points just beyond the last available location of the
output buffer. Use setp(0, 0) to indicate that no buffering
should be used. In that case overflow is called for every single
character to be written to the device.
virtual streamsize xsputn(char const *buffer, streamsize n):n characters to the output buffer. The actual
number of inserted characters is returned. If EOF is returned
writing to the device stops. The default implementation calls
sputc for each individual character. Redefine this member if,
e.g., the streambuf should support the ios::openmode ios::app.
Assuming the class MyBuf, derived from streambuf, features a
data member ios::openmode d_mode (representing the requested
ios::openmode), and a member write(char const *buf, streamsize
len) (writing len bytes at pptr()), then the following code
acknowledges the ios::app mode (see also section
14.8.2):
std::streamsize MyStreambuf::xsputn(char const *buf, std::streamsize len)
{
if (d_openMode & ios::app)
seekoff(0, ios::end);
return write(buf, len);
}
virtual streambuf *setbuf(char *buffer, streamsize n):pubsetbuf.
virtual ios::pos_type seekoff(ios::off_type offset,
ios::seekdir way, ios::openmode mode = ios::in | ios::out):ios::beg, ios::cur or ios::end). The
default implementation indicates failure by returning -1. This
function is called when tellg or tellp are called. When
derived class supports seeking, then it should also define this
function to handle repositioning requests. It is called by
pubseekoff. The new position or (by default) an invalid position
(i.e., -1) is returned (see also section 14.8.2).
virtual ios::pos_type seekpos(ios::pos_type offset,
ios::openmode mode = ios::in | ios::out):ios::beg). This function is called when seekg or
seekp are called. The new position or (by default) an invalid
position (i.e., -1) is returned.
virtual int sync():streambuf object ceases to exist.
streambuf at least underflow should
be overridden by classes intending to read information from devices, and
overflow should be overridden by classes intending to write information to
devices. Several examples of classes derived from streambuf are provided
in chapter 26.
Fstream class type objects use a combined input/output buffer,
resulting from istream and ostream being virtually derived from
ios, which class defines a streambuf. To construct a class
supporting both input and output using separate buffers, the streambuf
itself may define two buffers. When seekoff is called for reading, a
mode parameter can be set to ios::in, otherwise to ios::out. Thus
the derived class knows whether it should access the read buffer or the
write buffer. Of course, underflow and overflow do not have to
inspect the mode flag as they by implication know on which buffer they should
operate.
underflow
especially when buffers must repeatedly be refreshed and loaded. They are:
underflow and overflow.
uflow be overridden?
xsgetn.
xsputn.
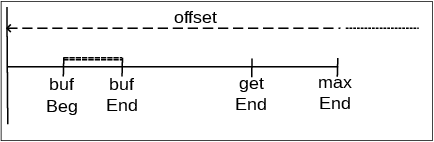
Figure 20 shows a situation where multiple buffers are used: the
device's information is made available in a buffer which is processed and
managed by the derived streambuf class. In this figure the following
variables are introduced:
offset is the device's current position. Its lower limit is 0,
and for all practical purposes there is no upper limit.
maxEnd, however, is the device's current physical maximum offset
value. Such a physical maximum may not exist, but it does exist if,
e.g., a physical buffer in memory is used which cannot contain more
than a fixed number of bytes. In those cases maxEnd is set to that
maximum value, representing the offset just beyond the highest offset
where a byte may be written to the device;
getEnd is the current maximum number of characters that can be read
from the device. With a newly defined device its value is 0 (zero),
but once bytes are written to the device getEnd is updated to the
position just beyond to the highest ever offset where a byte was
written. When disk-files are used getEnd would be equal to the
file's size;
streambuf's buffer. Instead it is split up in blocks of a
fixed size. The device's offset of the first byte of such a
block is available in bufBeg, and the offset just beyond the last
byte of such a block is available in bufEnd; bufEnd never
exceeds maxEnd.
This section covers how such multi-buffer data can be handled by iostream
objects: streams supporting reading and writing. Such streams offer
seekg and seekp members, but the device's offset position applies to
both seekg and seekp: after either seekg or seekp reading and
writing both start at the position defined by either of these two seek
members. Furthermore, when switching between reading and writing no
seekg/seekp call is required: by default new read or write requests
continue at the device's current offset, set by the last read, write, or seek
request.
seekg and seekp simply
compute the requested offset. Seek requests specifying ios::beg change
offset to the requested value. When ios::end is specified the offset
is computed relative to getEnd (since getEnd corresponds to the file
size of a physical disk-file ios::end should use getEnd as the current
end-offset and not maxEnd).
Computing offsets as shifts relative to the current offset is slightly
more complicated. When so far neither reading nor writing has been used
things are easy: the new offset equals the current offset plus the specified
ios::off_type sthift. But once information has just been read or written
things get complicated because offset doesn't correspond anymore to
the actual offset.
For example, initially, when information is written to the device's offset,
bufBeg and bufEnd are computed so that offset is located inside the
buffer starting at bufBegin and continuing to bufEnd, but thereafter
subsequent write requests are handled by the stream itself, and therefore
offset isn't updated. Instead only pptr()'s location, is updated,
invalidating offset.
Assume buffers are 100 bytes large, and in a concrete situation the buffer
covers the device's offsets 500 to 600 while offset equals 510. Then,
after writing "hello" pptr() is 515, but offset is still at
510. Consequently, in that situation issuing seekp(-5, ios::cur).tellp()
should not return 5 (i.e., offset - 5), but 10: bufBegin + pptr() -
pbase() - 5. A similar situation is encountered when reading: gptr() is
updated by read operations.
This problem is solved by introducing three states: the streambuf object
starts in the SEEK-state: the last-used operation wasn't reading or
writing. Once reading is used the state changes to READ, and to WRITE
once writing is used.
When s seek-request is issued the relative position depends on the current
state: in state SEEK the seek's shift value (as in seekg(shift,
ios::cur))is added to offset, in state READ it's added to bufBegin
+ gptr() - eback(), and in state WRITE it's added to bufBegin + pptr()
- pbase(). Seek-requests also change the state to SEEK, so subsequent
seek requests are computed relative to the last computed offset. Finally,
to ensure that underflow and overflow are called when subsequent read
or write operations are requested seek requests also reset setg and
setp by calling them with 0 (zero) arguments. Here is a skeleton
implementation of seekoff (assuming using namespace std):
ios::pos_type StreamBuf::seekoff(ios::off_type step,
ios::seekdir way, ios::openmode mode)
{
off_type offs;
switch (way)
{
default: // ios::beg: buffOffset is step
offs = step;
break;
case ios::cur:
switch (d_last)
{
// default: case SEEK
default: // no read/write used so far
offs = offset;
break; // add step to bufOffset (below)
case READ: // setg was used, set bufOffset to
// the abs offset of gptr()
offs = bufbeg + gptr() - eback();
break;
case WRITE: // setp was used, set bufOffset to
// the abs offset of pptr()
offs = bufbeg + pptr() - pbase();
// may extend the writing area
if (offs > static_cast<off_type>(getend))
getend = offs;
break;
}
offs += step; // add the step
break;
case ios::end:
offs = getend + step; // shift from the last write position
break;
}
if (offs < 0)
offs = 0; // offset always >= 0
d_last = SEEK;
setg(0, 0, 0); // reset the buffers
setp(0, 0);
return offset = offs; // the updated offset
}
overflow is called then the stream's write buffer is empty or
exhausted. The member underflow is called then the stream's read buffer is
empty or exhausted.
In both cases a new buffer (from bufBeg to bufEnd) is computed
containing offset. But offset depends on the streambuf's state. When
called in the SEEK state offset is up-to-date; when called in the
WRITE state the offset is at the last-used write offset; when called in
the READ state the current offset is at the end of the current read
buffer.
When called in the SEEK state the read and write buffers are already
empty. When called in the READ state the actual offset is determined and
the read buffer is reset to ensure that underflow is called at the next
read operation.
Likewise, when called in the WRITE state the write buffer is reset to
ensure that overflow is called at the next write request.
Both underflow and overflow therefore start by determining the current
offset, computing the corresponding buffer boundaries. The member getOffset
is called by both underflow and overflow. Here's its skeleton
implementation:
size_t StreamBuf::getOffset()
{
size_t offs;
switch (d_last)
{
default: // no buffers so far: use offset
offs = offset;
break;
case READ: // use the lastused read offset
offs = bufbeg + (gptr() - eback());
setg(0, 0, 0);
break;
case WRITE: // use the lastused write offset
offs = bufbeg + (pptr() - pbase());
setp(0, 0);
break;
}
bufLimits(offs); // set the buffer limits
return offs;
}
The member bufLimits simply ensures that offset is located inside a
buffer:
void StreamBuf::bufLimits(size_t offset)
{
bufbeg = offset / blockSize * blockSize;
bufend = bufbeg + blockSize;
if (bufend > maxend) // never exceed maxend
bufend = maxend;
}
The member overflow returns EOF or initializes a new read
buffer. Since overflow is guaranteed to be called when writing is
requested from states SEEK and READ it calls getOffset to obtain
the current absolute offset and the corresponding bufBeg en bufEnd
values. Writing can only be used if offset < maxEnd. If so, a new write
buffer is installed whose pptr() points at the offset position in the
physical device. After calling setp overflow must return ch on
success. Here's overflow's skeleton:
int StreamBuf::overflow(int ch) // writing
{
size_t offs = getOffset();
if (offs >= maxend) // at maxend: no more space
return EOF;
// define the writing buffer
setp(allData + bufbeg, allData + bufend);
pbump(offs - bufbeg); // go to the pos. to write the next ch
*pptr() = ch; // write ch to the buffere
pbump(1);
++offset;
// maybe enlarge getend
getend = max(getend, bufbeg + (pptr() - pbase()));
d_last = WRITE; // change to writing mode
// return the last written char
return static_cast<unsigned char>(ch);
}
The member underflow returns EOF or initializes a new read
buffer. Since underflow is guaranteed to be called when reading is
requested from states SEEK and WRITE it calls, like overflow,
getOffset to obtain the current absolute offset as well as the
matching bufBeg en bufEnd values. Reading can only be used if
offset < getEnd. If so, a new read buffer is installed whose gptr()
points at the offset position in the physical device.
As with overflow, after calling setg it's essential that the first
available character (i.e., *gptr()) is returned. If not and the buffer
contains just one character then that character might not be processed by
underflow's caller. Here's underflow's skeleton:
int StreamBuf::underflow()
{
offset = getOffset();
if (offset >= getend) // beyond the reading area
return EOF;
// define the reading buffer
setg(allData + bufbeg, allData + offset,
allData + min(getend, bufend));
d_last = READ;
return static_cast<unsigned char>(*gptr());
}
uflow be overridden? The function uflow is called when it's
available to return the next character from the device. In practice this is
handled by underflow, so there's probably little need for overriding
uflow. But if uflow is overridden then it must return the next
avaialble character and update gptr() to the next available
character. If the update isn't performed then the returned characters is
received twice by the stream. Here's a skeleton:
int StreamBuf::uflow()
{
if (gptr() == egptr() and underflow() == EOF)
return EOF;
unsigned char ch = *gptr();
gbump(1);
return ch;
}
seek requests seekg, seekp call seekoff. The member
streambuf::seekpos is maybe also called, but in practice
seekpos calls seekoff;
get calls underflow if there's no (or an exhausted) read
buffer. Otherwise it returns the character at gptr(), incrementing
its position;
>> calls underflow if there's no (or an exhausted) read
buffer. Otherwise if white-space characters are ignored (which is the
default) all white-space characters are skipped and the stream reads
the matching bytes from the read buffer, refreshing the buffer when
needed;
read calls xsgetn (which itself calls underflow) if there's
no or an exhausted read buffer, and tries to read the requested number
of characters from the device;
rdbuf() is used to insert the device's content from its current
offset position. It calls underflow and reads all the buffer's
characters until underflow returns EOF.
put calls overflow if there's no (or a filled up) write
buffer. Otherwise it returns the character at pptr(), incrementing
its position;
<< calls overflow if there's no (or a filled up) write
buffer. Otherwise the argument may be converted to characters (like
when insterting an int value) and the resulting characters are
inserted into the device, refreshing the buffer when needed;
write calls xsputn (which itself calls overflow) if there's
no or a filled up wrte buffer, and tries to write the requested number
of characters to the device.
read member calls xsgetn to read nChars characters from
the device. The nChar characters might not be available in the current
buffer. In those cases underflow is called to refresh the
buffer. Initially some bytes may already be available. At each cycle the
number of available characters are copied to the next location of its buf
parameter, calling underflow if there are no available characters
anymore. So xsgetn, while there are (still) characters to be read from the
device, must
underflow;
buf parameter;
buf pointer and the counters are updated using the
number of read bytes.
Here is a skeleton of xsgetn:
streamsize StreamBuf::xsgetn(char *buf, streamsize nChars)
{
size_t toRead = nChars;
size_t nRead = 0;
while (toRead)
{
size_t avail = egptr() - gptr(); // available buffer space
// no or empty memory buffer
// but no more readable chars
if (avail == 0 and underflow() == EOF)
return nRead;
avail = min(getend, bufend) - offset;
size_t next = min(avail, toRead); // next #bytes to write
memcpy(buf, gptr(), next); // write to the buffer
gbump(next); // update gptr
buf += next; // update the buf location
toRead -= next; // and update the counters
nRead += next;
offset += next;
}
d_last = READ; // now reading: also if underflow
// wasn't called.
return nRead;
}
write member calls xputn to write nChars characters
into the device. As with xsgetn the nChar characters might not be
available in the current buffer. In those cases overflow is called to
refresh the buffer. Room for some bytes may still be available, and at each
cycle the number of available locations are copied from the member's buf
parameter to the streambuf's write buffer, calling overflow if there's
no space available anymore in the current write buffer. So xsputn, while
there are (still) characters to be written to the device, must
overflow;
buf pointer and the counters are updated using the
number of written bytes.
Here is a skeleton of xsputn:
streamsize StreamBuf::xsputn(char const *buf, streamsize nChars)
{
size_t toWrite = nChars;
size_t nWritten = 0;
size_t offs = getOffset();
size_t avail = epptr() - pptr(); // available buffer space
while (toWrite)
{
if (avail == 0) // no space: try to reload
{ // the buffer
if (overflow(*buf) == EOF) // storage space exhausted?
break; // yes: done
++buf; // no: 1 byte was written
++nWritten;
++offs;
--toWrite;
avail = epptr() - pptr(); // remaining buffer space
if (avail == 0) // next cycle if avail == 0
continue;
}
size_t next = min(avail, toWrite); // next #bytes to write
memcpy(pptr(), buf, next); // write to the buffer
pbump(next); // update pptr
buf += next; // update the buf location
nWritten += next; // and update the counters
toWrite -= next;
offset = offs += next;
}
if (getend < offs + nWritten) // maybe enlarge the reading
getend = offs + nWritten; // area
d_last = WRITE; // WRITE state: now writing,
// maybe overflow wasn't used
return nWritten;
}
class filebuf is a specialization of streambuf used by the
file stream classes. Before using a filebuf the header file
<fstream> must be included.
In addition to the (public) members that are available through the class
streambuf, filebuf offers the following (public) members:
filebuf():Filebuf offers a public constructor. It initializes
a plain filebuf object that is not yet connected to a stream.
bool is_open():True is returned if the filebuf is actually connected to an
open file, false otherwise. See the open member, below.
filebuf *open(char const *name, ios::openmode mode):filebuf object with a file
whose name is provided. The file is opened according to the provided
openmode.
filebuf *close():filebuf
object and its file. The association is automatically closed when the
filebuf object ceases to exist.
Exception whose process member
would behave differently, depending on the kind of exception that was
thrown. Now that we've introduced polymorphism we can further develop this
example.
It probably does not come as a surprise that our class Exception should be
a polymorphic base class from which special exception handling classes can be
derived. In section 10.3.1 a member severity was used offering
functionality that may be replaced by members of the Exception base class.
The base class Exception may be designed as follows:
#ifndef INCLUDED_EXCEPTION_H_
#define INCLUDED_EXCEPTION_H_
#include <iostream>
#include <string>
class Exception
{
std::string d_reason;
public:
Exception(std::string const &reason);
virtual ~Exception();
std::ostream &insertInto(std::ostream &out) const;
void handle() const;
private:
virtual void action() const;
};
inline void Exception::action() const
{
throw;
}
inline Exception::Exception(std::string const &reason)
:
d_reason(reason)
{}
inline void Exception::handle() const
{
action();
}
inline std::ostream &Exception::insertInto(std::ostream &out) const
{
return out << d_reason;
}
inline std::ostream &operator<<(std::ostream &out, Exception const &e)
{
return e.insertInto(out);
}
#endif
Objects of this class may be inserted into ostreams but the core
element of this class is the virtual member function action, by default
rethrowing an exception.
A derived class Warning simply prefixes the thrown warning text by the
text Warning:, but a derived class Fatal overrides
Exception::action by calling std::terminate, forcefully
terminating the program.
Here are the classes Warning and Fatal
#ifndef WARNINGEXCEPTION_H_
#define WARNINGEXCEPTION_H_
#include "exception.h"
class Warning: public Exception
{
public:
Warning(std::string const &reason)
:
Exception("Warning: " + reason)
{}
};
#endif
#ifndef FATAL_H_
#define FATAL_H_
#include "exception.h"
class Fatal: public Exception
{
public:
Fatal(std::string const &reason);
private:
void action() const override;
};
inline Fatal::Fatal(std::string const &reason)
:
Exception(reason)
{}
inline void Fatal::action() const
{
std::cout << "Fatal::action() terminates" << '\n';
std::terminate();
}
#endif
When the example program is started without arguments it throws a
Fatal exception, otherwise it throws a Warning exception. Of
course, additional exception types could also easily be defined. To make the
example compilable the Exception destructor is defined above main. The
default destructor cannot be used, as it is a virtual destructor. In practice
the destructor should be defined in its own little source file:
#include "warning.h"
#include "fatal.h"
Exception::~Exception()
{}
using namespace std;
int main(int argc, char **argv)
try
{
try
{
if (argc == 1)
throw Fatal("Missing Argument") ;
else
throw Warning("the argument is ignored");
}
catch (Exception const &e)
{
cout << e << '\n';
e.handle();
}
}
catch (...)
{
cout << "caught rethrown exception\n";
}
The fundamental idea behind polymorphism is that the compiler does not know
which function to call at compile-time. The appropriate function is
selected at run-time. That means that the address of the function must be
available somewhere, to be looked up prior to the actual call. This
`somewhere' place must be accessible to the object in question. So when a
Vehicle *vp points to a Truck object, then vp->mass() calls
Truck's member function. The address of this function is obtained through
the actual object to which vp points.
Polymorphism is commonly implemented as follows: an object containing virtual member functions also contains, usually as its first data member a hidden data member, pointing to an array containing the addresses of the class's virtual member functions. The hidden data member is usually called the vpointer, the array of virtual member function addresses the vtable.
The class's vtable is shared by all objects of that class. The overhead of polymorphism in terms of memory consumption is therefore:
vp->mass first inspects the hidden
data member of the object pointed to by vp. In the case of the vehicle
classification system, this data member points to a table containing two
addresses: one pointer to the function mass and one pointer to the
function setMass (three pointers if the class also defines (as it
should) a virtual destructor). The actually called function is determined from
this table.
The internal organization of the objects having virtual functions is illustrated in Figure 21 and Figure 22 (originals provided by Guillaume Caumon).
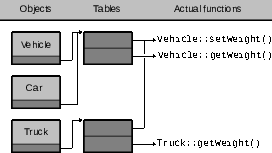
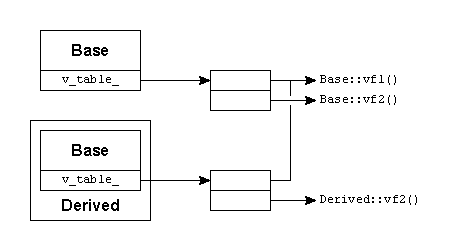
As shown by Figure 21 and Figure 22,
objects potentially using virtual member functions must have one (hidden) data
member to address a table of function pointers. The objects of the classes
Vehicle and Car both address the same table. The class Truck,
however, overrides mass. Consequently, Truck needs its own vtable.
A small complication arises when a class is derived from multiple base classes, each defining virtual functions. Consider the following example:
class Base1
{
public:
virtual ~Base1();
void fun1(); // calls vOne and vTwo
private:
virtual void vOne();
virtual void vTwo();
};
class Base2
{
public:
virtual ~Base2();
void fun2(); // calls vThree
private:
virtual void vThree();
};
class Derived: public Base1, public Base2
{
public:
~Derived() override;
private:
void vOne() override;
void vThree() override;
};
In the example Derived is multiply derived from Base1 and Base2,
each supporting virtual functions. Because of this, Derived also has
virtual functions, and so Derived has a vtable allowing a base class
pointer or reference to access the proper virtual member.
When Derived::fun1 is called (or a Base1 pointer pointing to a
Derived object calls fun1) then fun1 calls Derived::vOne and
Base1::vTwo. Likewise, when Derived::fun2 is called
Derived::vThree is called.
The complication
occurs
with Derived's vtable. When fun1 is called its class type determines
the vtable to use and hence which virtual member to call. So when vOne is
called from fun1, it is presumably the second entry in Derived's
vtable, as it must match the second entry in Base1's vtable. However, when
fun2 calls vThree it apparently is also the second entry in
Derived's vtable as it must match the second entry in Base2's vtable.
Of course this cannot be realized by a single vtable. Therefore, when multiple
inheritance is used (each base class defining virtual members) another
approach is followed to determine which virtual function to call. In this
situation (cf. figure Figure 23) the class Derived receives
two vtables, one for each of its base classes and each Derived
class object harbors two hidden vpointers, each one pointing to its
corresponding vtable.
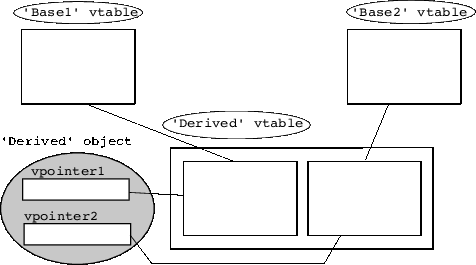
Since base class pointers, base class references, or base class interface members unambiguously refer to one of the base classes the compiler can determine which vpointer to use.
The following therefore holds true for classes multiply derived from base classes offering virtual member functions:
In function `Derived::Derived()':
: undefined reference to `vtable for Derived'
This error is generated when a virtual function's implementation is missing in a derived class, but the function is mentioned in the derived class's interface.
Such a situation is easily encountered:
undefined reference to `vtable for Derived'
class Base
{
virtual void member();
};
inline void Base::member()
{}
class Derived: public Base
{
void member() override; // only declared
};
int main()
{
Derived d; // Will compile, since all members were declared.
// Linking will fail, since we don't have the
// implementation of Derived::member()
}
It's of course easy to correct the error: implement the derived class's
missing virtual member function.
Virtual functions should never be implemented inline. Since the vtable contains the addresses of the class's virtual functions, these functions must have addresses and so they must have been compiled as real (out-of-line) functions. By defining virtual functions inline you run the risk that the compiler simply overlooks those functions as they may very well never be explicitly called (but only polymorphically, from a base class pointer or reference). As a result their addresses may never enter their class's vtables (and even the vtable itself might remain undefined), causing linkage problems or resulting in programs showing unexpected behavior. All these kinds of problems are simply avoided: never define virtual members inline (see also section 7.8.2.1).
According to the Prototype Design Pattern each derived class is given
the responsibility of implementing a member function returning a pointer to a
copy of the object for which the member is called. The usual name for this
function is clone. Separating the user interface from the reimplementation
interface clone is made part of the interface and newCopy is defined
in the reimplementation interface. A base class supporting `cloning' defines a
virtual destructor, clone, returning newCopy's return value and the
virtual copy constructor, a pure virtual function, having the prototype
virtual Base *newCopy() const = 0. As newCopy is a pure virtual
function all derived classes must now implement their own `virtual
constructor'.
This setup suffices in most situations where we have a pointer or
reference to a base class, but it fails when used with abstract
containers. We can't create a vector<Base>, with Base featuring the
pure virtual copy member in its interface, as Base is called to
initialize new elements of such a vector. This is impossible as newCopy is a
pure virtual function, so a Base object can't be constructed.
The intuitive solution, providing newCopy with a default
implementation, defining it as an ordinary virtual function, fails too as the
container calls Base(Base const &other), which would have to call
newCopy to copy other. At this point it is unclear what to do with
that copy, as the new Base object already exists, and contains no Base
pointer or reference data member to assign newCopy's return value to.
Alternatively (and preferred) the original Base class (defined as an
abstract base class) is kept as-is and a wrapper class Clonable is used
to manage the Base class pointers returned by newCopy. In chapter
17 ways to merge Base and Clonable into one class are
discussed, but for now we'll define Base and Clonable as separate
classes.
The class Clonable is a very standard class. It contains a pointer member
so it needs a copy constructor, destructor, and overloaded assignment
operator. It's given at least one non-standard member: Base &base() const,
returning a reference to the derived object to which Clonable's Base *
data member refers. It is also provided with an additional constructor to
initialize its Base * data member.
Any non-abstract class derived from Base must implement Base
*newCopy(), returning a pointer to a newly created (allocated) copy of the
object for which newCopy is called.
Once we have defined a derived class (e.g., Derived1), we can put our
Clonable and Base facilities to good use. In the next example we see
main defining a vector<Clonable>. An anonymous Derived1
object is then inserted into the vector using the following steps:
Derived1 object is created;
Clonable using Clonable(Base *bp);
Clonable object is inserted into the vector,
using Clonable's move constructor. There are only temporary Derived
and Clonable objects at this point, so no copy construction is required.
Clonable object containing the Derived1
* is used. No additional copies need to be made (or destroyed).
Next, the base member is used in combination with typeid to show
the actual type of the Base & object: a Derived1 object.
Main then contains the interesting definition vector<Clonable>
v2(bv). Here a copy of bv is created. This copy construction observes
the actual types of the Base references, making sure that the appropriate
types appear in the vector's copy.
At the end of the program, we have created two Derived1 objects, which
are correctly deleted by the vector's destructors. Here is the full program,
illustrating the `virtual constructor' concept (
Jesse van den Kieboom created an alternative implementation of a class
Clonable, implemented as a class template. His
implementation is found in the source archive under
contrib/classtemplates/.):
#include <iostream>
#include <vector>
#include <algorithm>
#include <typeinfo>
// Base and its inline member:
class Base
{
public:
virtual ~Base();
Base *clone() const;
private:
virtual Base *newCopy() const = 0;
};
inline Base *Base::clone() const
{
return newCopy();
}
// Clonable and its inline members:
class Clonable
{
Base *d_bp;
public:
Clonable();
explicit Clonable(Base *base);
~Clonable();
Clonable(Clonable const &other);
Clonable(Clonable &&tmp);
Clonable &operator=(Clonable const &other);
Clonable &operator=(Clonable &&tmp);
Base &base() const;
};
inline Clonable::Clonable()
:
d_bp(0)
{}
inline Clonable::Clonable(Base *bp)
:
d_bp(bp)
{}
inline Clonable::Clonable(Clonable const &other)
:
d_bp(other.d_bp->clone())
{}
inline Clonable::Clonable(Clonable &&tmp)
:
d_bp(tmp.d_bp)
{
tmp.d_bp = 0;
}
inline Clonable::~Clonable()
{
delete d_bp;
}
inline Base &Clonable::base() const
{
return *d_bp;
}
// Derived and its inline member:
class Derived1: public Base
{
public:
~Derived1() override;
private:
Base *newCopy() const override;
};
inline Base *Derived1::newCopy() const
{
return new Derived1(*this);
}
// Members not implemented inline:
Base::~Base()
{}
Clonable &Clonable::operator=(Clonable const &other)
{
Clonable tmp(other);
std::swap(d_bp, tmp.d_bp);
return *this;
}
Clonable &Clonable::operator=(Clonable &&tmp)
{
std::swap(d_bp, tmp.d_bp);
return *this;
}
Derived1::~Derived1()
{
std::cout << "~Derived1() called\n";
}
// The main function:
using namespace std;
int main()
{
vector<Clonable> bv;
bv.push_back(Clonable(new Derived1()));
cout << "bv[0].name: " << typeid(bv[0].base()).name() << '\n';
vector<Clonable> v2(bv);
cout << "v2[0].name: " << typeid(v2[0].base()).name() << '\n';
}
/*
Output:
bv[0].name: 8Derived1
v2[0].name: 8Derived1
~Derived1() called
~Derived1() called
*/