next returning the next fibonacci number at subsequent
calls. (Fibonacci numbers start with 0 and 1. The next fibonacci number
is the sum of the last two fibonacci numbers. The sequence, therefore, starts
with 0, 1, 1, 2, 3, 5, etc. In this and the following examples fibonacci
sequences are frequently used for illustration, and not because they are
inherently related to coroutines.)
Here is an example of how such a program could be designed: it defines a class
Fibo and in main Fibo::next is called to compute the next fibonacci
number (for brevity the program uses a single source file):
#include <iostream>
#include <string>
using namespace std;
class Fibo
{
size_t d_return = 0;
size_t d_next = 1;
public:
size_t next();
};
size_t Fibo::next()
{
size_t ret = d_return; // the next fibonacci number
d_return = d_next; // at the next call: return d_next;
d_next += ret; // prepare d_next as the sum of the
// original d_return and d_next
return ret;
}
int main(int argc, char **argv)
{
Fibo fibo; // create a Fibo object
size_t sum = 0;
// use its 'next' member to obtain
for ( // the sequence of fibonacci numbers
size_t begin = 0, end = argc == 1 ? 10 : stoul(argv[1]);
begin != end;
++begin
)
sum += fibo.next();
cout << sum << '\n';
}
Clearly the next member isn't all that complicated. But when it's called
several actions are performed which themselves are unrelated to computing
fibonacci numbers:
next is a
member function, so it does have an argument: the address of
the object for which next is called);
next function call on the stack;
next's arguments and local variables;
next's first instruction;
next's
local variables.
next's return statement has been executed:
These steps, although they look like a lot, in practice don't take that much time, because most of them are performed by very fast register operations, and the computer' architecture is usually highly optimized for these steps.
Nonetheless, in situations where the functions themselves are short and simple
(like Fibo::next) these steps, requiring stack- and register
manipulations, might be considered unwelcome, raising the question whether
they may be avoided.
C++ coroutines allow us to avoid executing the steps that are required
when calling ordinary functions. The upcoming sections cover coroutines in
depth, but here is, for starters, the coroutine's equivalent of
Fibo::next:
1: #include "main.ih"
2:
3: Fibo fiboCoro()
4: {
5: size_t returnFibo = 0;
6: size_t next = 1;
7:
8: while (true)
9: {
10: size_t ret = returnFibo;
11:
12: returnFibo = next;
13: next += ret;
14:
15: co_yield ret;
16: }
17: }
Already now we can observe some characteristics of the fiboCoro coroutine:
ret
to the coroutine's caller (the keyword co_yield is one of three
new keywords which can be used by coroutines; the other two being
co_await and co_return).
While fiboCoro lays the foundation for obtaining a sequence of
fibonacci numbers, resuming a coroutine doesn't mean calling a function the
way the above member Fibo::next is called: there are no arguments; there
is no preparation of local variables; and there is no stack
handling. Instead there's merely a direct jump to the instruction just beyond
the coroutine's suspension point. When the coroutine's code encounters the
next suspension point (which occurs in fiboCoro at it's next cycle,
when it again reaches its co_yield statement) then the program's execution
simply jumps back to the instruction following the instruction that resumed
the coroutine.
The main function using the coroutine looks very similar to the main
function using the class Fibo:
1: #include "main.ih"
2:
3: int main(int argc, char **argv)
4: {
5: Fibo fibo = fiboCoro();
6:
7: size_t sum = 0;
8:
9: for ( // the sequence of fibonacci numbers
10: size_t begin = 0, end = argc == 1 ? 10 : stoul(argv[1]);
11: begin != end;
12: ++begin
13: )
14: sum += fibo.next();
15:
16: cout << sum << '\n';
17: }
At line 5 fiboCoro is called, returning an (as yet not covered)
fibo thing. This fibo thing is called a
coroutine handler, and when (in line 14) fibo.next() is called, then
that call resumes fiboCoro, which is then again suspended at its
co_yield statement, returning the next available value through the
handler's next function.
The core feature of coroutines is thus that they may suspend their execution, while keeping their current state (values of variables, location of the next instruction to be executed, etc.). Normally, once suspended, the coroutine's caller resumes its work beyond the instruction that returned the coroutine's next value, so those two functions (the coroutine and its caller) closely cooperate to complete the implemented algorithm. Co-routines are therefore also known as cooperating routines, which should not be confused with concurrent (multi-threaded) routines.
How this whole process works, and what its characteristics are, is covered in the upcoming sections.
When defining coroutines the <coroutine> header file must be included.
A function is a coroutine once it uses the keywords co_yield,
co_await, or co_return. A coroutines cannot use the return
keyword, cannot define variadic parameters, and its return type must be an
existing type, which defines the coroutine's
handler.
Although coroutines appear to return objects (as suggested by the Fibo
return type of the Fibo fiboCoro() coroutine defined in the
previous section), in fact they do not. Instead coroutines return
so-called `handlers'. Such a handler is fibo, defined and used in the
previous section's main function:
int main(int argc, char **argv)
{
auto fibo = fiboCoro();
...
sum += fibo.next();
...
}
The class Fibo itself defines the characteristics allowing the compiler to
generate code storing the coroutine's arguments, its local variables, the
location of the next instruction to execute when the coroutine returns or is
suspended, and its so-called promise_type object on the heap. This only
happens once, so when the coroutine is activated (as in sum +=
fibo.next()) the steps which are normally taken when a function is called are
avoided, and instead the coroutine is immediately executed, using its already
available local variables and arguments.
Coroutine's handler classes are sometimes called Future, and their
nested state classes must be known as the handler's promise_type. The
names future and promise_type are completely unrelated to the
std::future (cf. section 20.8) and std::promise (cd. section
20.12) types which are used in the context of multi threading. In fact,
coroutines themselves are unrelated to multi threading, but are known as
cooperating routines. Because the coroutines' handler and state classes
are unrelated to the future and promise classes used in the context of
multi threading in this chapter the terms Handler and State are
generally used.
It's one thing to define a coroutine, but when using a coroutine its
handler-class (the Fibo class in the current example) must also be
defined. In addition, such a handler-class must define a
nested class whose name must be publicly available as the handler's
promise_type. The name promise_type doesn't very well cover its
purpose, and using a more descriptive class name might be preferred. In that
case a simple using declaration in the handler class's public section can be
used, as shown in the following basic design of the Fibo handler-class:
#include <coroutine>
class Fibo
{
class State // keeps track of the coroutine's state
{
...
};
std::coroutine_handle<State> d_handle;
public:
using promise_type = State;
explicit Fibo(std::coroutine_handle<State> handle);
~Fibo();
size_t next();
};
The coroutine's handler class has the following characteristics:
State) keeping track of the
couroutine's state;
std::coroutine_handle<State>, e.g.,
std::coroutine_handle<State> d_handle, whose members are covered
below;
promise_type a
using declaraction must be specified to make the nested class name
also known as promise_type;
next which was used in the example's main
function:
sum += fibo.next();
The next member's current implementation resumes the coroutine.
This doesn't mean that when next is called for the first time,
that it's the very first activation of the coroutine: the call auto
fibo = fiboCoro() comes first, and constructing and returning the
coroutine's handler (thereby suspending the coroutine at its very
first statement) is done automatically. At that point the caller
receives the coroutine's handler object, and constructing and
returning the handler object isn't visible in the coroutine's code
(more about that in the next section). Once suspended at co_yield
the value that's available in the coroutine's State is returned
and made available to the coroutine's caller:
size_t Fibo::next()
{
d_handle.resume();
return d_handle.promise().value();
}
The following members can be called via the Handler's d_handle data
member:
void *address() returning the address of the handler's
State object;
void destroy(), returning the State object's memory
to the operating system. It ends the State object's
existence. Usually the handler class's destructor calls
d_handle.destroy();
bool done(), returning true when the coroutine has
returned, and false if it's currently suspended;
coroutine_handle from_address(void *address) returns
a coroutine_handle corresponding to the address of a handler's
State object, which address is passed to the function as its
argument. A nullptr can also be passed to from_address;
explicit operator bool(), returning
true if d_handle is not a null-pointer. It's commonly used in
the handler's destructor's if (d_handle) phrase. It returns
false after assigning 0 (or nullptr) to d_handle. This
operator and static_cast<bool>(d_handle.address()) act identically
(note that d_handle.address() is still valid after assigning 0 to
d_handle, in which case it returns 0);
State &promise(), returning a reference to
the Handler's State class;
void resume()
(or void operator()()) resumes the execution of a suspended
coroutine. Resuming a coroutine is only defined if the coroutine is
actually suspended.
The Handler's State class keeps track of the coroutine's state. Its basic
elements are covered in the next section.
Handler::State keeps track of the coroutine's state. It must
publicly be known as the class Handler::promise_type, which can be
realized using a public using-declaration associating a more appropriately
named class with `promise_type'.
In the current example the class name State is used, having the following
interface:
class State
{
size_t d_value;
public:
Fibo get_return_object();
std::suspend_always yield_value(size_t value);
static std::suspend_always initial_suspend();
static std::suspend_always final_suspend() noexcept;
static void unhandled_exception();
static void return_void();
size_t value() const;
};
This State class doesn't declare a constructor, so its default
constructor is used. It's also possible to declare and define the default
constructor. Alternatively, by declaring and defining a constructor that has
the same parameters as its coroutine (or parameters that can be initialized by
the coroutine's parameters) that constructor is called when the coroutine
returns its handling object. E.g., if a coroutine's signature is
Handler coro(int value, string const &str);
and the State class has a constructor
Handler::State::State(int value, string const &str);
then that constructor is called. State's default constructor is called
if such a constructor is not available. In addition to calling State's
constructor a coroutine can also use an awaiter to pass arguments to the
handler's State class. This method is covered in section 24.5.
The data member d_value and member function value() are specifically
used by the class Fibo, and other coroutine state classes might declare
other members. The remaining members are required, but the members returning
std::suspend_always could also be declared
as members returning std::suspend_never.
By returning the (empty) structs suspend_always the coroutine's actions
are suspended until resumed. In practice suspend_always is used, and so
the ..._suspend members can be declared static, using these basic
implementations:
inline std::suspend_always Fibo::State::initial_suspend()
{
return {};
}
inline std::suspend_always Fibo::State::final_suspend() noexcept
{
return {};
}
Likewise, the unhandled_exception member can be declared static when
it simply retrows exceptions that may be thrown by the coroutine:
inline void Fibo::State::unhandled_exception()
{ // don't forget: #include <future>
std::rethrow_exception(std::current_exception());
}
The (required) member Fibo::State::get_return_object returns an
object of the coroutine's handling class (so: Fibo). The recipe is:
from_promise of an anonymous object of the
class std::coroutine_handle<State>;
Fibo);
Fibo object is then returned by
State::get_return_object.
Here is Fibo::State::get_return_object's implementation:
inline Fibo Fibo::State::get_return_object()
{
return Fibo{ std::coroutine_handle<State>::from_promise(*this) };
}
The member Fibo:State::yield_value can be overloaded for different
argument types. In our Fibo::State there's only one yield_value
member, storing its parameter value in the State::d_value data member. It
also suspends the coroutine's execution as it returns std::suspend_always:
inline std::suspend_always Fibo::State::yield_value(size_t value)
{
d_value = value;
return {};
}
Now that the coroutine's handling class and its State subclass have been
covered, let's have a closer look at what happens when the main function
from the introductory section is executed. Here's main once again:
1: int main(int argc, char **argv)
2: {
3: auto fibo = fiboCoro();
4:
5: size_t sum = 0;
6:
7: for ( // the sequence of fibonacci numbers
8: size_t begin = 0, end = argc == 1 ? 10 : stoul(argv[1]);
9: begin != end;
10: ++begin
11: )
12: sum += fibo.next();
13:
14: cout << sum << '\n';
15: }
When called with argument `2' the following happens:
fiboCoroutine is called (see the
introduction section 24 for its definition),
but before that:
State::get_return_object is called, returning a Fibo
object. Note here that fiboCoroutine itself nowhere returns a
Fibo object, even though its definition suggests that it does.
The get_return_object member does call Fibo's
constructor though, and this Fibo object is returned at line
3.
Fibo object the
coroutine's execution is suspended (as
Fibo::State::initial_suspend is automatically called).
Fibo object is assigned to
fibo. The current implementation uses auto fibo = ..., but
Fibo fibo = ... may also be used. Using auto might be
attractive if the name of the coroutine handling class's type is
rather convoluted;
main's execution continues at line 12 where fibo.next() is
called;
fibo.next() resumes the coroutine by calling d_handle.resume().
As this is the very first time that the coroutine is explicitly called
it now starts its execution at the first statement written by the
coroutine's author;
co_yield, co_await, or co_return keyword. In this case it's
co_yield, returning the current fibonacci value (size_t ret);
State::yield_value member whose parameter type matches
ret's type exists, that member is called, receiving ret's
value as its argument. As yield_value returns
std::suspend_always the coroutine is again suspended;
Fibo::next's next
statement, where Fibo's d_handle uses its member promise() to
reach the handler's State object, allowing next to return
State::value() (which is the most recently computed fibonacci
value, stored in the State
object when State::yield_value was called).
Fibo::next() returns that value;
for-statement continues at line 7,
once again reaching line 12.
co_yield statement). So it doesn't
continue at the coroutine's first statement but continues its
execution by performing the statements of its while (true)
statement until again reaching its co_yield statement, as
described above;
for-statement ends, and just before the
program ends (at line 15) Fibo's destructor is automatically
called, returning the memory allocated for the coroutine's data to the
common pool.
std::suspend_always State's members return
std::suspend_never? In that case the coroutine, once it has started, is is
never suspended. If the program computing fibonacci numbers is then called
with argument 2, the following happens:
fiboCoroutine is called,
but before that:
State::get_return_object is called, returning a Fibo object
at line 3.
Fibo object the
coroutine's execution continues, as this time
Fibo::State::initial_suspend doesn't suspend. The fibo
object, however, has been constructed since auto fibo = ...
isn't an assignment but an initialization of the fibo object.
co_yield. But although
Fibo::State::yield_value is called at co_yield calls the
coroutine isn't suspended, as yield_value now returns
suspend_never.
State::d_value at each subsequent iteration. Since the
loop isn't suspended and since there's no other exit from the
loop, the program continues until it's terminated by some signal (like
ctrl-C).
Looking at the Fibo::State class, its members initial_suspend,
final_suspend and unhandled_exception are good candidates for such a base
class. By defining the base class as a class template, receiving the coroutine
handler's class name and the handler's state class name as its template type
parameters then it can also provide the handler's get_return_object
member.
Here is how this base class can be defined. It is used by the coroutine handler's state classes developed in this chapter:
#include <cstddef>
#include <future>
#include <coroutine>
template <typename Handler, typename State>
struct PromiseBase
{
Handler get_return_object();
static std::suspend_always initial_suspend();
static std::suspend_always final_suspend() noexcept;
static void unhandled_exception();
static void return_void();
};
template <typename Handler, typename State>
inline void PromiseBase<Handler, State>::return_void()
{}
template <typename Handler, typename State>
inline std::suspend_always PromiseBase<Handler, State>::initial_suspend()
{
return {};
}
template <typename Handler, typename State>
inline std::suspend_always PromiseBase<Handler, State>::final_suspend() noexcept
{
return {};
}
template <typename Handler, typename State>
inline void PromiseBase<Handler, State>::unhandled_exception()
{
std::rethrow_exception(std::current_exception());
}
template <typename Handler, typename State>
inline Handler PromiseBase<Handler, State>::get_return_object()
{
return Handler{ std::coroutine_handle<State>::from_promise(
static_cast<State &>(*this) )
};
}
In this section we develop a class Floats that can either write or read
binary float values to or from files. An object of this
class is used in main, calling its member run to either write or read
a binary file (the full program is available in the distribution's
coroutines/demo/readbinary directory):
int main(int argc, char **argv)
{
Floats floats(argc, argv);
floats.run();
}
The program is called with two arguments: r for reading, or w for
writing, and the name of the binary file as its second argument.
The member Floats:run uses pointers to members to call either read or
write:
class Reader;
class Writer;
class Floats
{
enum Action
{
READ,
WRITE,
ERROR,
};
Action d_action;
std::string d_filename; // name of the binary file
static void (Floats::*s_action[])() const; // pointers to read and write
public:
Floats(int argc, char **argv);
void run() const;
private:
void read() const;
Reader coRead() const;
void write() const;
static Writer coWrite();
};
inline void Floats::run() const
{
(this->*s_action[d_action])();
}
The member read reads the binary file, using the coroutine
coRead. When coRead is called the usual actions are performed:
implicitly the coroutine Reader's State member get_return_object is
called to obtain the coroutine's handler, and the coroutine is suspended. Next
the handler returned by get_return_object is made available as the
read function's reader object:
void Floats::read() const
{
Reader reader = coRead(); // coRead: the coroutine
// reader: the coroutine's handler
while (auto opt = reader.next()) // retrieve the next value
cout << opt.value() << ' ';
cout << '\n';
}
Once the reader object is available the member read enters a while
loop repeatedly calling reader.next(). At this point the following
happens:
next has returned, the read function again continues,
either ending its while-statement or showing the retrieved
float.
When resumed for the first time (so when reader.next() is called for the
first time) the coRead coroutine opens the file, and then, in a
while-statement, determines the next available value. If that succeeds the
coroutine is again suspended, using co_yield to pass the just read value
on to read, or (if no value could be obtained) the coroutine ends by
calling co_return. Here is the Floats::coRead coroutine:
Reader Floats::coRead() const
{
ifstream in{ d_filename };
while (true)
{
float value;
in.read(reinterpret_cast<char *>(&value), sizeof(float));
if (not in)
co_return; // if not: end the coroutine
co_yield value;
}
}
Likewise, the member write (re)writes the binary file, using the coroutine
coWrite, following the same procedure as used by read to obtain the
writer coroutine handler:
void Floats::write() const
{
ofstream out{ d_filename };
Writer writer = coWrite(); // coWrite: the coroutine,
// writer: the coroutine's handler
cout << "Enter values (one per prompt), enter 'q' to quit\n";
while (true)
{
cout << "? ";
auto opt = writer.next(); // retrieve the next value
if (not opt) // stop if no more values
break;
out.write(&opt.value()[0], sizeof(float));
}
}
The member Floats::coWrite behaves like Floats::coRead, but writes
instead of reads values to the binary file. Here is coWrite, defined as a
normal (non-static) member, as it uses Floats::d_filename:
Writer Floats::coWrite()
{
while (true)
{
float value;
if (not (cin >> value)) // get the next value
co_return; // if not: end the coroutine
Writer::ValueType ret; // value to return
ret = Writer::ValueType{ string{
reinterpret_cast<char const *>(&value),
reinterpret_cast<char const *>(&value + 1) }
};
co_yield ret;
}
}
The Reader and Writer handler classes are covered next.
Reader class is that its State subclass receives a
value from the coroutine (coRead) at the coroutine's co_yield
statement. Reader::State receives the value that's passed to co_yield
as argument of its yield_value member, which stores the received float
value in its std::optional<float> d_value data member.
The Reader class itself must define a constructor receiving a handle to
its State class , and should define a destructor. Its next member
simply returns the value that's stored in its State class to next's
caller. Here is Reader's complete header file:
#include <iostream>
#include <optional>
#include "../../promisebase/promisebase.h"
struct Reader
{
using ValueType = std::optional<float>;
private:
class State: public PromiseBase<Reader, State>
{
ValueType d_value;
public:
std::suspend_always yield_value(float value);
void return_void();
ValueType const &value() const;
};
std::coroutine_handle<State> d_handle;
public:
using promise_type = State;
explicit Reader(std::coroutine_handle<State> handle);
~Reader();
ValueType const &next();
};
Reader's and Reader::State's members have (except for Reader::next)
very short implementations which can very well be defined inline:
inline std::suspend_always Reader::State::yield_value(float value)
{
d_value = value;
return {};
}
inline void Reader::State::return_void()
{
d_value = ValueType{};
}
inline Reader::ValueType const &Reader::State::value() const
{
return d_value;
}
inline Reader::Reader(std::coroutine_handle<State> handle)
:
d_handle(handle)
{}
inline Reader::~Reader()
{
if (d_handle)
d_handle.destroy();
}
Reader::next performs two tasks: it resumes the coroutine, and then, once
the coroutine is again suspended (at its co_yield statement), it returns
the value stored in the Reader::State object.
It can access its State class object via
d_handle.promise(), returning the value stored in that object:
Reader::ValueType const &Reader::next()
{
d_handle.resume();
return d_handle.promise().value();
}
Writer class closely resembles the Reader class. It uses a
different value type, as it must write float values to the output stream
using their binary representations, but other than that there aren't that many
difference with the Reader class. Here is its interface and the
implementations of its yield_value member that differs from that of the
Reader class:
struct Writer
{
using ValueType = std::optional<std::string>;
private:
class State: public PromiseBase<Writer, State>
{
ValueType d_value;
public:
std::suspend_always yield_value(ValueType &value);
void return_void();
ValueType const &value() const;
};
std::coroutine_handle<State> d_handle;
public:
using promise_type = State;
explicit Writer(std::coroutine_handle<State> handle);
~Writer();
ValueType const &next();
};
inline std::suspend_always Writer::State::yield_value(ValueType &value)
{
d_value = std::move(value);
return {};
}
co_yield and co_return. What about
co_await? The verb to await is more formal than to wait, but the
two verbs mean the same. The added level of formality of to await is
illustrated by a second description offered by the Merrian Webster
dictionary: to remain in abeyance until, and abeyance's meaning takes
us home again: a state of temporary inactivity or suspension. So when
co_await is used the coroutine enters a state of temporary inactivity,
i.e., it is suspended. In that sense co_yield is no different, as it also
suspends the coroutine, but different from co_yield co_await expects a
so-called awaitable expression. I.e., an expression resulting in an
Awaitable, or that is convertible to an Awaitable
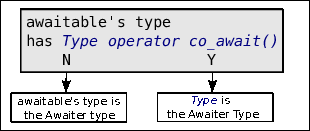
object (see also figure 32).
Figure 32 shows that the expression that's passed to
co_await may be an Awaitable object, or if the coroutine handle's
State class has a member await_transform accepting an argument of some
expr's type, the value returned by await_transform is the
Awaitable (cf. figure 33). These await_transform members
may be overloaded, so in any concrete situation several Awaitable types
could be used.
The Awaiter type that's eventually used is either an object of
co_await's expr's type, or it is the return type of the (implicitly called
when defined) coroutine handler's State::await_transform(expr) member.
Thus, the Awaitable object is a middle-man, that's only used to obtain
an Awaiter object. The Awaiter is the real work-horse in the context
of co_await.
Awaitable classes may define a member
Awaiter Awaitable::operator co_await(), which may also be provided as a
free function (Awaiter operator co_await(Awaitable &&)). If such a
co_await conversion operator is available then it is used to obtain the
Awaiter object from the Awaitable object. If such a conversion
operator is not available then the Awaitable object is the
Awaiter object.
As an aside: the types Awaitable and Awaiter are used here as formal
class names, and in actual programs the software engineer is free to use other
(maybe more descriptive) names.
Awaiter object is available its member bool
await_ready() is called. If it returns true then the coroutine is not
suspended, but continues beyond its co_await statement (in which case
the Awaitable object and Awaiter::await_ready were apparently able to
avoid suspending the coroutine).
If await_ready returns false
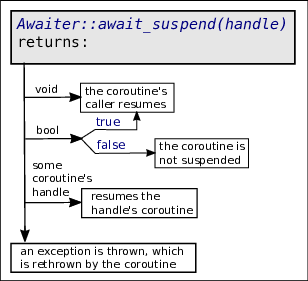
Awaiter::await_suspend(handle) is called. Its handle argument is the
handle (e.g., d_handle) of the current coroutine's handler object. Note
that at this point the coroutine has already been suspended, and the
coroutine's handle could even be transferred to another thread (in which case
the current thread must of course not be allowed to resume the current
coroutine). The member await_suspend may return void, bool, or some
coroutine's handle (optionally its own handle). As illustrated in figure
34, when returning void or true the coroutine is
suspended and the coroutine's caller continues its execution beyond the
statement that activated the coroutine. If false is returned the coroutine
is not suspended, and resumes beyond the co_await statement. If a
coroutine's handle is returned (not a reference return type, but value return
type) then the coroutine whose handle is returned is resumed (assuming that
another coroutine's handle is returned than the current coroutine is
suspended, and the other coroutine (which was suspended up to now) is resumed;
in the next section this process is used to implement a finite state automaton
using coroutines)
If, following await_suspend, the current coroutine is
again resumed, then just before that the Awaiter object calls
Awaiter::await_resume(), and await_resume's return value is returned
by the co_await expression (await_resume) frequently defines a
void return type, as in
static void Awaiter::await_resume() const
{}
In the next section a finite state automaton is implemented using
coroutines. Their handler classes are also Awaiter types, with
await_ready returning false and await_resume doing nothing. Thus
their definitions can be provided by a class Awaiter acting as base class
of the coroutines' handler classes. Awaiter only needs a simple header
file:
struct Awaiter
{
static bool await_ready();
static void await_resume();
};
inline bool Awaiter::await_ready()
{
return false;
}
inline void Awaiter::await_resume()
{}
State, and a using declaration is used to make it known as
promise_type which is required by the standard facilities made available
for coroutines.
When coroutines are suspended at co_yield statements, the yielded values
are passed to State class's yield_value members whose parameter
types match the types of the yielded values.
In this section we reverse our point of view, and discuss a method allowing
the coroutine to reach facilities of the State class. We've already
encountered one way to pass information from the coroutine to the State
class: if the State class's constructor defines the same parameters as the
coroutine itself then that constructor is used, receiving the coroutine's
parameters as arguments.
But let's assume that the coroutine performs a continuous loop containing
several, maybe conditional, co_yield statements, and we want to inform the
State class what the current iteration cycle is. In that case a parameter
is less suitable, as tracking the cycle number is in fact a job for one of the
local variables of the coroutine, which would look something like this:
Handler coroutine()
{
size_t cycleNr = 0;
// make cycleNr available to tt(Handler's State) class
while (true)
{
++cycleNr; // now also known to tt(Handler's State)
... // the coroutine at work, using various co_yield
// statements
}
}
Awaiters can also be used in these kinds of situations, setting up
communication lines between coroutines and the State classes of their
Handler class objects. As an illustration, the original
fibocoro coroutine 24 was slightly modified:
1: Fibo fiboCoroutine()
2: {
3: size_t returnFibo = 0;
4: size_t next = 1;
5: size_t cycle = 0;
6:
7: co_await Awaiter{ cycle };
8: cerr << "Loop starts\n";
9:
10: while (true)
11: {
12: ++cycle;
13:
14: size_t ret = returnFibo;
15:
16: returnFibo = next;
17: next += ret;
18:
19: co_yield ret;
20: }
21: }
size_t cycle is defined, keeping track of the
coroutine's iteration cycle;
co_await statemenent, passing co_await an
object that receives the cycle, which is the variable the
Handler's State should know about;
cycle is incremented, so it contains the current
iteration cycle.
The Awaiter object, since there's no State::await_transform member,
is an awaitable. Neither does Awaiter have a Type operator
co_await(), so the anonymous Awaiter object is indeed an Awaiter.
Being the Awaiter, it defines three members: await_ready, merely returning
false, as the coroutine's execution must be suspended at the co_await
statement; await_suspend(handle), receiving a handle to the coroutine's
Handler's State object; and await_resume, which doesn't have to do
anything at all:
class Awaiter
{
size_t const &d_cycle;
public:
Awaiter(size_t const &cycle);
bool await_suspend(Fibo::Handle handle) const;
static bool await_ready();
static void await_resume();
};
inline Awaiter::Awaiter(size_t const &cycle)
:
d_cycle(cycle)
{}
inline bool Awaiter::await_ready()
{
return false;
}
inline void Awaiter::await_resume()
{}
The member await_suspend uses the received handle to access the State
object, passing cycle to State::setCycle:
bool Awaiter::await_suspend(Fibo::Handle handle) const
{
handle.promise().setCycle(d_cycle);
return false;
}
In the next section (24.6) we use await_suspend to switch from
one coroutine to another, but that's not required here. So the member returns
false, and thus continues its execution once it has passed cycle to
State::setCycle. This way coroutines can pass information to the
Handler's State object, which could define a data member size_t const
*d_cycle and a member setCycle, using d_cycle in, e.g.,
yield_value:
inline void Fibo::State::setCycle(size_t const &cycle)
{
d_cycle = &cycle;
}
std::suspend_always Fibo::State::yield_value(size_t value)
{
std::cerr << "Got " << value << " at cycle " << *d_cycle << '\n';
d_value = value;
return {};
}
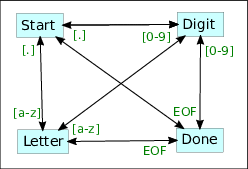
Flexc++ to recognize letters, digits or
other characters it defines three input categories, and 4 states (the first
state being the INITIAL state determining the next state based on the
character read from the scanner's input stream, the other three being the
states that handle characters from their specific categories).
FSAs can also be implemented using coroutines. When using coroutines each
coroutine handles a specific input category, and determines the category to
use next, given the current input category. Figure 35 shows a simple
FSA: at Start a digit takes us to Digit, a letter to Letter, at
any other character we remain in Start, and at end of file (EOF) we end
the FSA at state Done. Digit and Letter act analogously.
This FSA uses four coroutines: coStart, coDigit, coLetter, and coDone,
each returning their own handlers (like a Start handler returned by
coStart, a Digit handler by coDigit, etc.). Here is
coStart:
1: Start coStart()
2: {
3: char ch;
4: while (cin.get(ch))
5: {
6: if (isalpha(ch))
7: {
8: cout << "at `" << ch << "' from start to letter\n";
9: co_await g_letter;
10: }
11: else if (isdigit(ch))
12: {
13: cout << "at `" << ch << "' from start to digit\n";
14: co_await g_digit;
15: }
16: else
17: cout << "at char #" << static_cast<int>(ch) <<
18: ": remain in start\n";
19: }
20: co_await g_done;
21: }
The flow of this coroutine is probably self-explanatory, but note the
co_await statements at lines 9, 14, and 20: at these lines the
co_awaits realize the switch from the current coroutine to another. How
that's realized is soon described.
The coroutines coDigit and coLetter perform similar actions, but
coDone, called at EOF, simply returns, thus ending the coroutine-based
processing of the input stream. Here's coDone, simply using co_return
to end its lifetime:
Done coDone()
{
cout << "at EOF: done\n";
co_return;
}
Now take a look at this short input file to be processed by the program:
a
1
a1
1a
when processing this input the program shows its state changes:
at `a' from start to letter
at char #10: from letter to start
at `1' from start to digit
at char #10: from digit to start
at `a' from start to letter
at `1' from letter to digit
at char #10: from digit to start
at `1' from start to digit
at `a' from digit to letter
at char #10: from letter to start
at EOF: done
Since coroutines are normally suspended once activated, the Start handler
privides a member go starting the FSA by resuming its coroutine:
void Start::go()
{
d_handle.resume(); // maybe protect using 'if (d_handle)'
}
The main function merely activates the Start coroutine, but the
coroutines might of course also be embedded in something like a class FSA,
and main might offer an option to process a file argument instead of using
redirection. Here's main:
int main()
{
g_start.go();
}
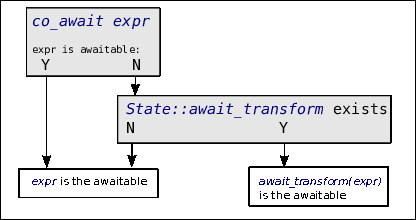
co_await
expr statement. The shortest route goes like this:
expr is an awaitable if the
current coroutine's State class does not have an
await_transform member. In that case expr is the awaitable;
expr's type does not
have an operator co_await member then expr's type is the
Awaiter.
So, the nested Start::State class only has to provide the standard
members of the coroutine handler's State class. As those are all provided
by the generic PromiseBase class (section 24.1.2) State needs
no additional members:
// nested under the Start handler class:
struct State: public PromiseBase<Start, State>
{};
Similar considerations apply to the other three handler classes: their
State classes are also derived from PromiseBase<Handler,
State>. However, as the coDone coroutine also uses co_return, the
Done::State state class must have its own a return_void member:
// nested under the Done handler class:
struct State: public PromiseBase<Done, State>
{
void return_void() const;
};
// implementation in done.h:
inline void Done::State::return_void() const
{}
As our FSA allows transitions from Digit and Letter back to
Start the Start handler class itself is an Awaiter (as are Digit,
Letter, and Done). Section 24.4 described the requirements and
basic definition of Awaiter classes.
From the point of view of FSAs the most interesting part is how to switch from
one coroutine to another. As illustrated in figure 34 this
requires a member await_suspend which receives the handle of the
coroutine using the co_await statement, and returns some coroutine's
handle. So:
co_await expr is used, where expr is a coroutine's handler, which
is also an Awaiter;
expr's
await_suspend member;
expr's await_suspend member determines
which coroutine is resumed, suspending the coroutine using
co_await;
expr returns its own handle, thereby realizing the FSA's state switch
from the current coroutine to expr's coroutine.
Here is the interface of coStart's handler class as well as the definition
of its await_suspend member. Since the coStart coroutine may be
resumed by several other coroutines it is unknown which coroutine's handle was
passed to Start::await_suspend, and so await_suspend is a member
template, which simply returns Start's handle.
class Start: public Awaiter
{
struct State: public PromiseBase<Start, State>
{};
std::coroutine_handle<State> d_handle;
public:
using promise_type = State;
using Handle = std::coroutine_handle<State>;
explicit Start(Handle handle);
~Start();
void go();
// this and the members in Awaiter are required for Awaiters
template <typename HandleType>
std::coroutine_handle<State> await_suspend(HandleType &handle);
};
template <typename HandleType>
inline std::coroutine_handle<Start::State>
Start::await_suspend(HandleType &handle)
{
return d_handle;
}
As the member Start's wait_suspend returns Start's d_handle, the
coroutine containing the co_await g_start statement is suspended, and the
co_start coroutine is resumed (see also figure 34).
The implementations of the Start handler's constructor and destructor are
straightforward: the constructor stores the coroutine's handle in its
d_handle data member, the destructor uses the (language provided) member
destroy to properly end the Start::State's coroutine handle. Here are
their implementations:
Start::Start(Handle handle)
:
d_handle(handle)
{}
Start::~Start()
{
if (d_handle)
d_handle.destroy();
}
Digit and Letter coroutines handler classes are implemented
like Start. Like coStart, which continues its execution when a
non-digit and non-letter character is received, coDigit continues for as
long as digit characters are received, and coLetter continues for as long
as letter characters are received.
As we've seen in section 24.6 the implementation of coDone is a
bit different: it doesn't have to do anything, and the coDone coroutine
simply ends at its co_return statement. Coroutine execution (as well as
the FSA program) then ends following main's g_start.go() call.
The complete implementation of the coroutine-based FSA program is available in
the Annotation's distribution under the directory
yo/coroutines/demo/fsa.
For starters, consider a very simple interactive program that produces a
series of numbers until the user ends the program or enters q:
1: int main()
2: {
3: Recursive rec = recursiveCoro(true);
4:
5: while (true)
6: {
7: cout << rec.next() << "\n"
8: "? ";
9:
10: string line;
11: if (not getline(cin, line) or line == "q")
12: break;
13: }
14: }
At line 3 the recursiveCoro coroutine is called, returning its handler
rec. In line 7 its member next is called, returning the next value
produced by recursiveCoro. The function recursiveCoro could
have been any function returning an object of a class that has a next
member. For now ignoring recursion, recursiveCoro could look like this:
1: namespace
2: {
3: size_t s_value = 0;
4: }
5:
6: Recursive recursiveCoro(bool recurse)
7: {
8: while (true)
9: {
10: for (size_t idx = 0; idx != 2; ++idx)
11: co_yield ++s_value;
12:
13: // here recursiveCoro will recursively be called
14:
15: for (size_t idx = 0; idx != 2; ++idx)
16: co_yield ++s_value;
17: }
18: }
The coroutine merely produces the sequence of non-negative integral
numbers, starting at 0. Its two for-loops (lines 10 and 15) are there merely
for illustrative purposes, and the recursive call will be placed between those
for-loops. The variable s_value is defined outside the coroutine (instead
of using static s_value = 0 inside), as recursively called coroutines must
all access the same s_value variable. There's no magic here: just two
for-statements in a continuously iterating while-statement.
The interface of the returned Recursive object isn't complex either:
1: class Recursive
2: {
3: class State: public PromiseBase<Recursive, State>
4: {
5: size_t d_value;
6:
7: public:
8: std::suspend_always yield_value(size_t value);
9: size_t value() const;
10: };
11:
12: private:
13: using Handle = std::coroutine_handle<State>;
14: Handle d_handle;
15:
16: public:
17: using promise_type = State;
18:
19: explicit Recursive(Handle handle);
20: ~Recursive();
21:
22: size_t next();
23: bool done() const;
24: };
The required members of its State class are available in
PromiseBase (cf. section 24.1.2) and do not have to be
modified. As recursiveCoro co_yields values, the State::yield_value
member stores those values in its d_value data member:
std::suspend_always Recursive::State::yield_value(size_t value)
{
d_value = value;
return {};
}
Its member value is an accessor, returning d_value. When recursion
is used the recursive calls end at some point. When recursiveCoro
functions end State::return_void is called. It doesn't have to do
anything, so PromiseBase's empty implementation perfectly does the job.
The Recursive handling class's own interface starts at line 12. Its
d_handle data member (line 14) is initialized by its constructor (line
19), which is all the constructor has to do. The handler's destructor only has
to call d_handle.destroy() to return the memory used by its State
object.
The remaining members are next and done. These, too, are implemented
straight-forwardly. The member done will shortly be used in the recursive
implementation of recursiveCoro, and it just returns the value returned by
d_handle.done().
When the member next is called the coroutine is in its suspended state
(which is what happens when it's initially called (cf. line 3 in the above
main function) and thereafter when it uses co_yield (lines 11 and 16
in the above implementation of recursiveCoro)). So it resumes the
coroutine, and when the coroutine is again suspended, it returns the (next
available) value stored in the handler's State object:
size_t Recursive::next()
{
d_handle.resume();
return d_handle.promise().value();
}
recursiveCoro coroutine into a recursively
called coroutine. To activate recursion recursiveCoro is modified by
adding some extra statements below line 8:
1: Recursive recursiveCoro(bool recurse)
2: {
3: while (true)
4: {
5: for (size_t idx = 0; idx != 2; ++idx)
6: co_yield ++s_value;
7:
8: // here recursiveCoro will recursively be called
9:
10: if (not recurse)
11: break;
12:
13: Recursive rec = recursiveCoro(false);
14:
15: while (true)
16: {
17: size_t value = rec.next();
18: if (rec.done())
19: break;
20:
21: co_yield value;
22: }
23:
24: for (size_t idx = 0; idx != 2; ++idx)
25: co_yield ++s_value;
26: }
27: }
Recursion is activated when the parameter recurse is true, which is
passed to recursiveCoro when initially called by main. It is then
recursively called in line 13, now using false as its argument. Consider
what happens when it's recursively called: the while-loop is entered and the
for-statement at line 5 is executed, `co_yielding' two values. Next, in line
10, the loop ends, terminating the recursion. This implicitly calls
co_return. It's also possible to do that explicitly, using
if (not recurse)
co_return;
Going back to the initial call: once rec (line 13) is available, a
nested while-loop is entered (line 15), receiving the next value obtained by
the recursive call (line 17). That next call resumes the nested coroutine,
which, as just described, returns two values when executing line 5's
for-statement. But then, when it's resumed for the third time, it doesn't
actually co_yield a newly computed value, but calls co_return (because
of lines 10 and 11), thus ending the recursive call. At that point
the coroutine's State class's member done returns true, which
value is available through ret.done() (line 18). Once that happens the
while loop at line 15 ends, and the non-recursive coroutine continues at line
24. If the recursively called coroutine does compute a value,
rec.done() returns false, and value produced by rec is
`co_yielded' by the non-recursively called coroutine, making it available to
main. So in that latter case the value co_yielded by the recursively
called coroutine is co_yielded by the initially called coroutine, where it is
retrieved by main: there's a sequence of co_yield statements from the
most deeply nested coroutine to the coroutine that's called by main,
at which point the value is finally collected in main.
The next..done implementation used here resembles the way streams are
read: first try to extract information from a stream. If that succeeds, use
the value; if not, do something else:
while (true)
{
cin >> value;
if (not cin)
break;
process(value);
}
Functions like getline and overloaded extraction operators may combine
the extraction and the test. That's of course also possible when using
coroutines. Defining next as
bool Recursive::next(size_t *value)
{
d_handle.resume();
if (d_handle.done()) // no more values
return false;
*value = d_handle.promise().value();
return true;
}
allows us to change the while loop at line 15 into:
size_t value;
while (rec.next(&value))
co_yield value;
fiboCoro coroutine was presented. In
this section the fiboCoro coroutine is going to be used by the
recursiveCoro coroutine, using multiple levels of recursion.
To concentrate on the recursion process the fiboCoroutine's handler is
defined in main as a global object, so it can directly be used by every
recursive call of recursiveCoro. Here is the main function, using
bool Recursive::next(size_t *value), and it also defines the global object
g_fibo:
Fibo g_fibo = fiboCoro();
int main()
{
Recursive rec = recursiveCoro(0);
size_t value;
while (rec.next(&value))
{
cout << value << "\n"
"? ";
string line;
if (not getline(cin, line) or line == "q")
break;
}
}
The Recursive class interface is identical to the one developed in the
previous section, except for the Recursive::done member (which is not used
anymore and was therefore removed from the interface), and changing next
member's signature as shown. It's implementation was altered accordingly:
bool Recursive::next(size_t *value)
{
d_handle.resume();
if (d_handle.done())
return false;
*value = d_handle.promise().value();
return true;
}
In fact, the only thing that has to be modified to process deeper recursion
levels is the recursiveCoro coroutine itself. Here is its modified
version:
1: Recursive recursiveCoro(size_t level)
2: {
3: while (true)
4: {
5: for (size_t idx = 0; idx != 2; ++idx)
6: co_yield g_fibo.next();
7:
8: if (level < 5)
9: {
10: Recursive rec = recursiveCoro(level + 1);
11: size_t value;
12: while (rec.next(&value))
13: co_yield value;
14: }
15:
16: for (size_t idx = 0; idx != 2; ++idx)
17: co_yield g_fibo.next();
18:
19: if (level > 0)
20: break;
21: }
22: }
This implementation strongly resembles the 1-level recursive coroutine. Now
multiple levels of recursion are allowed, and the maximum recursion level is
set at 5. The coroutine knows its own recursion level via its size_t level
parameter, and it recurses as long as level is less than 5 (line 8). At
each level two series of two fibonacci values are computed (in the
for-statements at lines 5 and 16). After the second for-statement the
coroutine ends unless it's the coroutine that's called from main, in which
case level is 0. The decision to end (recursively called) coroutines is
made in line 19.
In this implementation the maximum recursion level is set to a fixed value. It's of course also possible that the coroutine itself decides that further recursion is pointless. Consider the situation where directory entries are examined, and where subdirectories are handled recursively. The recursive directory visiting coroutine might then have an implementation like this:
1: Recursive recursiveCoro(string const &directory)
2: {
3: chdir(directory.c_str()); // change to the directory
4:
5: while ((entry = nextEntry())) // visit all its entries
6: {
7: string const &name = entry.name();
8: co_yield name; // yield the entry's name
9:
10: if (entry.type() == DIRECTORY) // a directory?
11: { // get the full path
12: string path = pathName(directory, name);
13: co_yield path; // yield the full path
14:
15: auto rec = recursiveCoro(path); // visit the entries of
16: string next; // the subdir (and of its
17: while (rec.next(&next)) // subdirs)
18: co_yield next; // and yield them
19: }
20: }
21: }
In this variant the (not implemented here) function nextEntry (line 5)
produces all directory entries in sequence, and if an entry represents a
directory (line 10), the same process is performed recursively (line 15),
yielding its entries to the current coroutine's caller (line 18).
begin and end members
returning iterators.
Coroutines (or actually, their handling classes) may also define begin and
end members returning iterators. In practice those iterators are input
iterators (cf. section 18.2), providing access to the values
co_yielded by their coroutines. Section 22.14 specifies their
requirements. For plain types (like size_t which is co_yielded by
Fibo::next) iterators should provide the following members:
Iterator &operator++());
Type &operator*());
bool operator==(Iterator const &other))
(and maybe operator!= returning its complement).
The Iterator class is a value class. However, except for copy- and
move-constructions, Iterator objects can only be constructed by
Recursive's begin and end members. It has a private constructor
and declares Recursive as its friend:
class Iterator
{
friend bool operator==(Iterator const &lhs, Iterator const &rhs);
friend class Recursive;
Handle d_handle;
public:
Iterator &operator++();
size_t operator*() const;
private:
Iterator(Handle handle);
};
Iterator's constructor receives Recursive::d_handle, so it can use
its own d_handle to control recursiveCoro's behavior:
Recursive::Iterator::Iterator(Handle handle)
:
d_handle(handle)
{}
The member Recursive::begin ensures that Iterator::operator* can
immediately provide the next available value by resuming the coroutine. If
that succeeds it passes d_handle to Iterator's constructor. If
there are no values it returns 0, which is the Iterator that's also
returned by Recursive::end:
Recursive::Iterator Recursive::begin()
{
if (d_handle.promise().level() == 0)
g_fibo.reset();
d_handle.resume();
return Iterator{ d_handle.done() ? 0 : d_handle };
}
Recursive::Iterator Recursive::end()
{
return Iterator{ 0 };
}
The dereference operator simply calls and returns the value returned by
State::value() and the prefix increment operator resumes the coroutine. If
no value was produced it assigns 0 to its d_handle, resulting in true
when compared to the iterator returned by Recursive::end:
size_t Recursive::Iterator::operator*() const
{
return d_handle.promise().value();
}
Recursive::Iterator &Recursive::Iterator::operator++()
{
d_handle.resume();
if (d_handle.done())
d_handle = 0;
return *this;
}
This section covers a coroutine that visits all elements of (nested) directories, listing all their path-names relative to the original starting directory. First a more traditional approach is covered, using a class having a member that recursively visits directory elements. Thereafter a coroutine is described performing the same job. Finally, some statistics about execution times of both approaches are discussed.
Dir is developed (recursively) showing all entries
in and below a specified directory. The program defines a class Dir,
used by main:
int main(int argc, char **argv)
{
Dir dir{ argc == 1 ? "." : argv[1] };
while (char const *entryPath = dir.entry())
cout << entryPath << '\n';
}
The class Dir, like the coroutine based implementation in the next
section, uses the `dirent' C struct. As we prefer typenames starting
with capitals, Dir specifies a simple using DirEntry = dirent
so C's typename doesn't have to be used.
Dir defines just a few data members:
d_dirPtr stores the pointer returned by C's function opendir;
d_recursive points to a Dir entry that's used to handle a
sub-directory of the current directory;
d_entry is the name of the directory
returned by Dir::entry member, which is refreshed at each call;
d_path stores the name of the directory visited by a Dir object;
and d_entryPath is d_entry's path name, starting at the initial
directory name.
Here is Dir's class interface:
class Dir
{
using DirEntry = dirent;
DIR *d_dirPtr = 0;
Dir *d_recursive = 0;
char const *d_entry; // returned by entry()
std::string d_path; // Dir's directory name, ending in '/'
std::string d_entryPath;
public:
Dir(char const *dir); // dir: the name of the directory to visit
~Dir();
char const *entry();
};
Dir's constructor prepares its object for inspection of the entries of the
directory whose name is received as its argument: it calls
opendir for that directory, and prepares its d_path data member:
Dir::Dir(char const *dir)
:
d_dirPtr(opendir(dir)), // prepare the entries
d_path( dir )
{
if (d_path.back() != '/') // ensure that dirs end in '/'
d_path += '/';
}
Once a Dir object's lifetime ends its destructor simply calls
closedir to return the memory allocated by opendir:
inline Dir::~Dir()
{
closedir(d_dirPtr);
}
The member entry performs two tasks: first, if a recursion is active then
if a recursive entry is available, that entry is returned. Otherwise, if
no recursive entry is available d_recursive's memory is deleted, and
d_recursive is set to 0:
// first part
if (d_recursive) // recursion active
{
if (char const *entry = d_recursive->entry()) // next entry
return entry; // return it
delete d_recursive; // delete the object
d_recursive = 0; // end the recursion
}
The second part is executed if there's no recursion or once all the recursive
entries have been obtained. In that case all entries of the current directory
are retrieved, skipping the two mere-dot entries. If the thus obtained entry
is the name of a directory then d_recursive stores the address of a newly
allocated Dir object (which is then handled at Dir::entry's next call)
and the just received entry name is returned:
// second part
while (DirEntry const *dirEntry = readdir(d_dirPtr))// visit all entries
{
char const *name = dirEntry->d_name; // get the name
if (name == "."s or name == ".."s) // ignore dot-names
continue;
name = (d_entryPath = d_path + name).c_str(); // entry-name
// (as path)
if (dirEntry->d_type == DT_DIR) // a subdir?
d_recursive = new Dir{ name }; // handle it next
return name; // return the entry
}
The member Dir::entry itself consists of these two parts, returning zero
(no more entries) once the second part's while-loop ends:
char const *Dir::entry()
{
// first part here
// second part here
return 0;
}
Thus, the class Dir essentially requires one single member function, using
recursion to visit all directory entries that exist in or below the specified
starting directory. All sources of this program are available in the
distribution's yo/coroutines/demo/dir directory.
The source files of this program are available in the distribution's
yo/coroutines/demo/corodir directory. It uses the same DirEntry
type definition as used in the previous section, and specifies
using Pair = std::pair<DirEntry, char const *> to access a
DirEntry and its path name.
The program's main function strongly resembles the main function using
the class Dir, but this time main uses the visitAllEntries
coroutine:
int main(int argc, char **argv)
{
char const *path = argc == 1 ? "." : argv[1];
for (auto [entry, entryPath ]: visitAllEntries(path))
cout << entryPath << '\n';
}
The main function uses a range-based for-loop to show the entries produced
by the visitAllEntries coroutine, which are the files and directories that
are (recursively) found in a specified starting directory.
Three coroutines are used to process directories. The visitAllEntries
coroutine returns a RecursiveGenerator<Pair> as its handler. Like
main, the visitAllEntries coroutine also uses a range-based for-loop
(line 3) to retrieve directory entries. The coroutine yields Pair objects
(line 5) or the results from nested directories (line 9). Its handler (a
RecursiveGenerator) is a class template, defined in Lewis Baker's
cppcoro library:
1: RecursiveGenerator<Pair> visitAllEntries(char const *path)
2: {
3: for (auto &entry_pair: dirPathEntries(path))
4: {
5: co_yield entry_pair;
6:
7: auto [entry, entry_path] = entry_pair;
8: if (entry.d_type == DT_DIR)
9: co_yield visitAllEntries(entry_path);
10: }
11: }
Directory entries are made available by a second coroutine,
dirPathEntries. At each entry visitAllEntries is suspended (line 5),
allowing main to show its full path. At lines 7 and 8 the types of the
entries are inspected. If the received entry refers to a sub-directory then
visitAllEntries yields, recursively calling itself, and thus yielding the
sub-directory's entries. Once all entries have been processed the range-based
for-loop ends, and the coroutine ends by automatically calling co_return.
The coroutine yielding directory entries is dirPathEntries, whose handler
is an object of another cppcoro class, Generator<Pair>:
1: Generator<Pair> dirPathEntries(char const *path)
2: {
3: for (auto const &entry: dirEntries(path))
4: co_yield make_pair(entry,
5: (string{path} + '/' + entry.d_name).c_str());
6: }
The dirPathEntries coroutine performs a cosmetic task: it receives the
path name of a directory, and calls a third coroutine (dirEntries) to
retrieve the successive elements of that directory (line 3). As long as there
are entries the coroutine is suspended, yielding Pair objects consisting
of the values returned by dirEntry and the full path names of those
entries (lines 4 and 5). Eventually, as with visitAllEntries, co_return
ends the coroutine.
The third coroutine is dirEntries, returning a Generator<DirEntry
handler:
1: Generator<DirEntry> dirEntries(char const *path)
2: {
3: DIR *dirPtr = opendir(path);
4:
5: while (auto entry = readdir(dirPtr))
6: {
7: if (accept(*entry))
8: co_yield *entry;
9: }
10: closedir(dirPtr);
11: }
This coroutine, like the Dir class from the previous section, uses
C's opendir, readdir, and closedir triplet of functions. As
coroutines resume their actions beyond their suspension points these functions
can now all be used in a single coroutine. When dirEntries starts, it
calls opendir (line 3). Then, as long as there are entries (line 5) and
those entries are neither the current nor the parent directory (line 7,
checked by accept, not listed here), the coroutine is suspended, yielding
the obtained entry (line 8). Its while-loop ends once all entries have been
retrieved. At that point closedir is called (line 10), and the coroutine
ends.
co_yields simply suspend coroutines, leaving all their data,
ready to be (re)used, in the heap.
In many situations coroutines are considered more attractive at an intuitive level: already in the introductory section of this chapter they were characterized as cooperating routines, where the coroutine cooperates with its caller, producing the caller's requested information as if the coroutine is part of the caller's code. But although it formally isn't it can conceptually be considered part of the caller's code, as it doesn't have to be called again and again during the caller's lifetime: once activated the coroutine remains available in memory and doesn't have to be called again when it's resumed. Coroutines are cooperating in that sense: they can in fact be considered part of the caller's code. In this way they really differ from independent functions which, when called repeatedly, are called again and again `from scratch', implying intensive stack operations.
On the other hand, using coroutines is way more complex than using
`traditional' functions. The source files of the discussed Dir class
required some 100 lines of source code, whereas the coroutine based
implementation needed about 700 lines of code. But maybe that's not a fair
comparison. Maybe the cppcoro library's sources shouldn't be considered,
like when we're using --say-- strings, streams and vectors, in which case we
also ignore the sizes of their sources when they're used in our programs. If
we do ignore the sizes of cppcoro's sources, then the coroutine based
implementation in fact requires fewer lines of code than the Dir
class, as the Generator and RecursiveGenerator handler classes are
provided by the cppcoro library.
Eventually, implementing parts of algorithms with coroutines, instead of using
the (functions based) structured programming approach, might simply be a
matter of taste. But maybe, as coroutines allow us to split up algorithms in
separate parts which are not using stack-based activations, the efficiency of
coroutine-based implementations exceeds the efficiency of implementations
using separate supoprt functions. To get some information about the efficiency
of programs using coroutines vs. programs that use separate support functions
the class Dir based program and the coroDir based program was each run
five times, processing a large multi-directory, multi-file structure,
containing over 400.000 entries. The execution times of each of the five runs
are highly comparable. The following table shows the average clock-times, the
average user-times, and the average system-times for the class Dir based
program and the coroDir based program:
| time | ||||
| real | user | system | ||
| class Dir | 82 | 22 | 59 | |
| coroDir | 88 | 25 | 62 | |
class Dir implementation uses slightly less time than the
coroDir implementatin, the differences are small, and should not be
interpreted as an indication that (maybe different from what was expected)
coroutine based implementations are inherently slower than function based
implementations. Furthermore, coroutines themselves often call ordinary
functions (like readdir called by coroDir's coroutine
dirEntries), which still require stack-handling.
The conclusion at the end of this chapter is therefore that, yes, coroutines
are available in C++, but they require lots of effort before they can be
used. Some libraries (like cppcoro) are available, but they're not (yet?)
part of the software that comes standard with your C++ compiler. However,
the underlying philosophy (being able to use cooperating routines) certainly
is attractive, although it doesn't necessarily result in more efficient
programs than programs which are developed using the traditional structured
programming approach. And so, in the end, whether or not to use coroutines
might simply boil down to a matter of taste.